
heketi安装结合EFK实践
这是一个k8s集群,搭建gluster fs系统提供存储服务,搭建heketi进行管理gluster fs,结合k8s的StorageClass进行动态pv建立。提供给生产环境的日志收集系统EFK存储数据。
准备环境
- 操作系统:centos7
- 硬盘:/dev/vdc 50Gi
GlusterFS
搭建glusterfs来作为可持续存储k8s的CSI
安装glusterfs
三台服务器都要执行
1 | 先安装 gluster 源 |
配置 glusterfs
三台服务器都要执行
配置本地解析文件hosts
1 | echo """ |
开放端口(24007是gluster服务运行所需的端口号)如果关闭了防火墙就省略此步操作。其他防火墙设置自己解决
1 | iptables -I INPUT -p tcp --dport 24007 -j ACCEPT |
搭建完毕glusterFS
heketi
本项目参考github地址:
https://github.com/huisebug/heketi.git
安装客户端
下载地址:
https://github.com/heketi/heketi/releases/
1 | tar zxf heketi-client-v9.0.0.linux.amd64.tar.gz |
创建ssh key并分发
在所有的glusterfs节点,创建hekeli的数据库存储目录、ssh免密码登录文件目录。
1 | mkdir -p /data/heketi/{db,.ssh} && chmod 700 /data/heketi/.ssh |
如果执行操作的节点可以免密登录到其他节点就可以执行下面命令,不行就手动分发
1 | for NODE in node1 node2 node3; do scp -r /data/heketi/.ssh root@${NODE}:/data/heketi; done |
手动分发
1 | cat /data/heketi/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys |
运行heketi
运行原理
Heketi服务使用建立的ssh key登录到gluster fs服务器的root账户,然后就可以执行gluster fs服务进行管理。
需要三个文件
- heketi-deployment.yaml:heketi服务运行yaml,其中需要声明登录到glusterfs的方式,
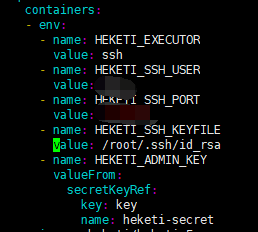
需要指定ssh登录用户,此处我是root;ssh服务端口号,此处我未使用默认的22端口
此处指定了node进行部署,所以记得修改你的节点特有的标签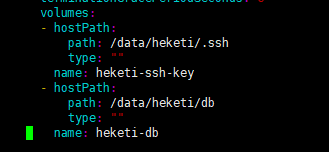
之前在所有运行gluster fs的服务器建立了/data/heketi/文件目录,这里指定其中节点运行就都可以使用hostPath方式volume,将生成的ssh key挂载到heketi服务中,让其可以远程发送命令操作gluster fs所在服务器,进行pv、vg管理(概念参考地址:https://www.cnblogs.com/zk47/p/4753987.html) - heketi-secret.yaml:这是设置登录到heketi服务的密码
- heketi-svc.yaml:因为我们需要使用客户端heketi-cli进行集群的创建,所以这里需要使用NodePort的方式进行访问
执行安装
1 | kubectl apply -f heketi-deployment.yaml -f heketi-secret.yaml |

验证
这里配置Heketi的service在NodeIP:30944上
通过命令检查heketi服务
1 | curl -s <http://api.328ym.com:30944/hello> |

导入glusterfs集群拓扑(topology)信息
文件内容heketi-topology-vdc.json
参考heketi-topology-vdc.json文件地址:
https://raw.githubusercontent.com/huisebug/heketi/master/heketi-topology-vdc.json
- hostnames下的manage和storage配置为gluster的IP地址;
- zone可以配置为非0值,这里配置为1,;
- devices下制定gluster fs服务器下的文件驱动,例如:/dev/sdb,指定多个文件驱动!!!
- destroydata:是否销毁文件驱动的数据,这里使用了true
有关glusterfs集群的topology的配置参考
https://github.com/heketi/heketi/blob/master/docs/admin/topology.md
执行
1 | heketi-cli --user admin --secret password --server http://api.328ym.com:30944 topology load --json heketi-topology-vdc.json |
查看heketi服务日志(kubectl logs -f heketi-7749795dc7-k6qnb)如果提示如下错误
1 | [sshexec] ERROR 2019/04/28 07:41:01 |
报错原因是无法手动向警告提示输入y或n,解决方法:
1 | 那么就手动到所有gluster fs服务的命令行手动建立pv |
执行后,每个节点出现ok就说明成功建立,可以使用vgscan命令进行查看。
查看集群id
1 | heketi-cli --user admin --secret password --server http://api.328ym.com:30944 cluster list |

建立volume
非k8s使用
1 | heketi-cli --user admin --secret password --server http://10.142.21.21:30088 volume create --size=100 --replica=3 --clusters=38c2729af0f42338cf66eed6b80f116f |
k8s使用
此处使用动态PV的方式,建立storageclass和pvc进行关联,然后动态建立pv
建立StorageClass
1 | apiVersion: storage.k8s.io/v1 |
执行
1 | kubectl apply -f heketi-storageclass.yaml |
建立pvc
1 | kind: PersistentVolumeClaim |
执行
1 | kubectl apply -f heketi-test-pvc.yaml |
查看volume建立情况
1 | heketi-cli --user admin --secret password --server http://api.328ym.com:30944 volume list |

查看是否建立pvc和自动建立pv
查看gluster fs 卷信息和挂载情况
查看卷的使用情况和集群情况
1 | heketi-cli --user admin --secret password --server http://api.328ym.com:30944 topology info |
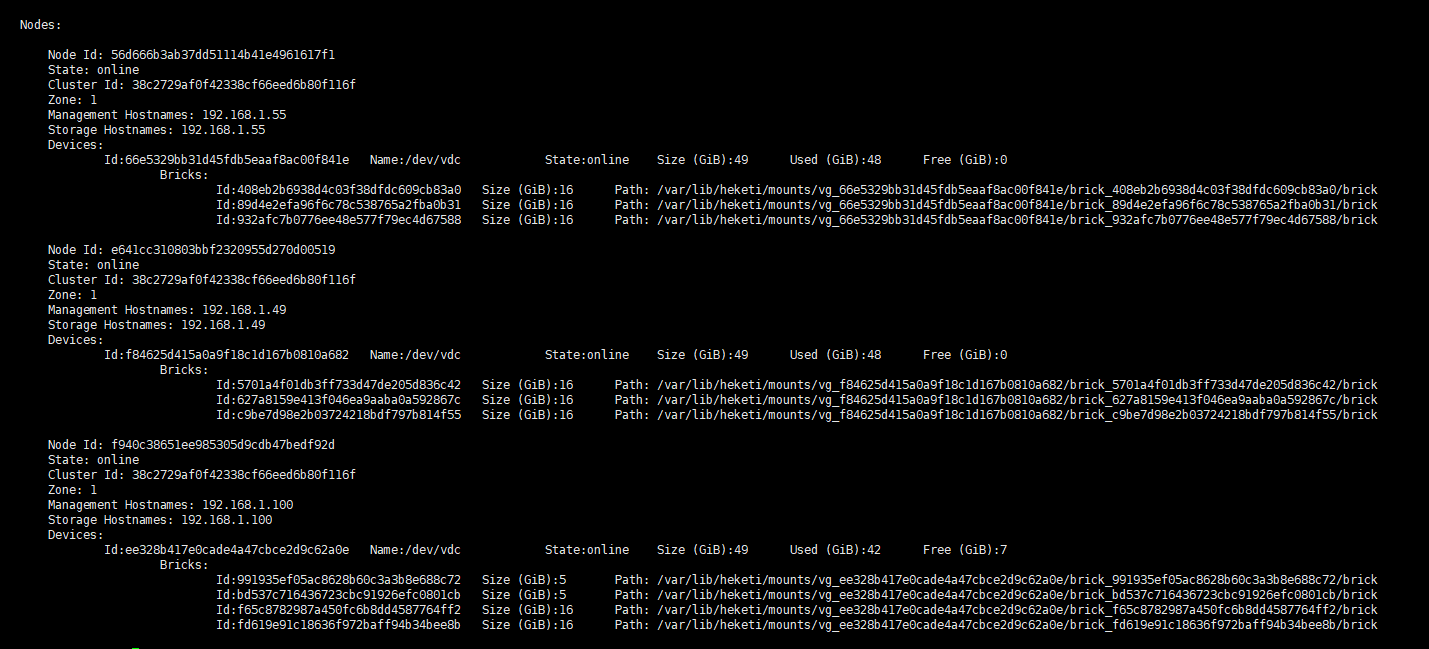
实践
###实践###
此处我们的gluster fs是使用了三块50Gi的硬盘组成的集群,验证当申请超过50Gi的时候会如何建立,能否建立成功?
- 我们复制之前的test-pvc 文件,将其修改为如下heketi-test-pvc2.yaml
1
cp -rf heketi-test-pvc.yaml heketi-test-pvc2.yaml
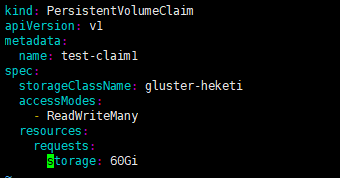
执行
查看挂载情况
难道说这里使用了30Gi,会平均从其他gluster节点划取空间?
查看gluster fs信息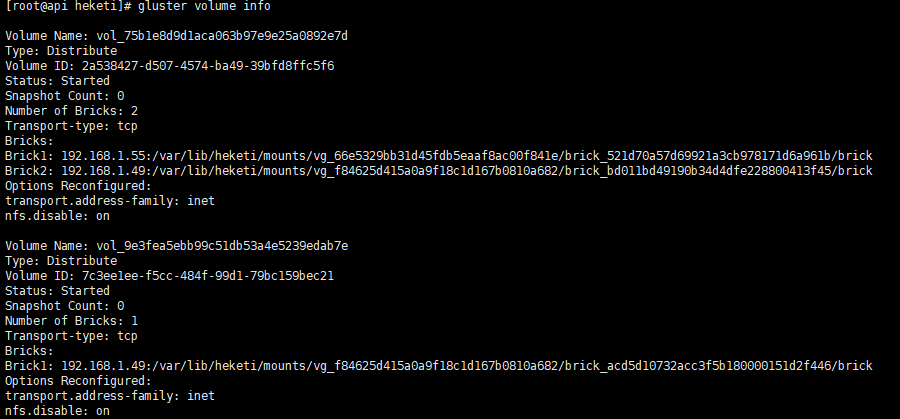
获取到另一个来源是192.168.1.55这台服务器,切换到这台服务器进行查看
果然证实了我的猜测。
查看pvc和pv
删除pvc配置
pv也会自动删除
EFK
作为整个集群的日志系统,我们可以使用三台性能优越的服务器安装好kubelet、kube-proxy、docker后将其作为node加入到现有的集群中去,并将其打上efk的标签,不允许其他pod调度到服务器上面。
列如:
1 | kubectl label node efk1.huisebug.com efknode=efk |
我这里就不这样进行操作了,还是将efk服务安装到整个集群中
yaml文件下载地址
参考我的git地址
1 | git clone https://github.com/huisebug/EFK.git |
ElasticSearch
- ES的官网推荐,不太推荐使用分布式文件系统(NFS/GlusterFS等)来进行数据的存储,对ES的性能会造成很大的影响。
- 这里我就不使用之前搭建的GlusterFS系统了。使用 local-storage(1.9版本引入,将本地存储以PV形式提供给容器进行使用,实现存储空间的管理)作为storageClassName,PVC概念参考官方网址
https://www.kubernetes.org.cn/pvpvcstorageclass
local-storage
三台服务器都要执行
新加硬盘
所以此处我们新加硬盘来建立local-storage
我这里是虚拟机,可以直接增加新硬盘SCSI接口硬盘进行热插拔,不重启系统,刷新出硬盘
1 | ls /sys/class/scsi_host/ |
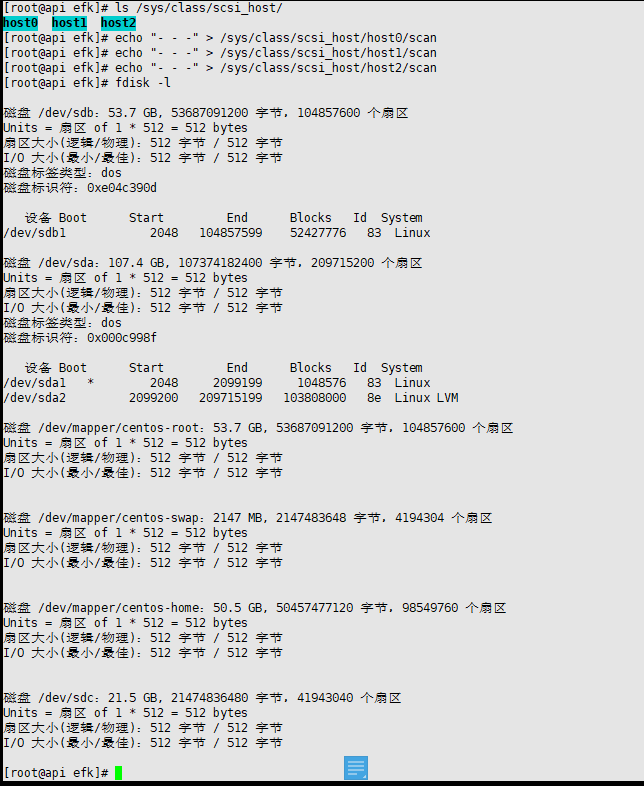
上面的sdc硬盘20G就是我新加的硬盘
分区格式化并挂载到各宿主机的/data目录
1 | fdisk -l /dev/sdc |
建立相应的PV
参考地址:
https://github.com/huisebug/EFK/blob/master/efkyaml/es-pv-api.yaml
https://github.com/huisebug/EFK/blob/master/efkyaml/es-pv-node1.yaml
https://github.com/huisebug/EFK/blob/master/efkyaml/es-pv-node2.yaml
注意:存储大小,别超过实际大小;指定正确的存储类型;指定正确的本地路径;指定连接的服务器主机名
- accessModes:
- ReadWriteOnce 注意这里定义的访问模式是单个节点读写。即一个pv只给一个pvc使用,像我们这里是3个pv,那么只能有3个pod调用pv,就算定义为ReadWriteMany也是如此。 - 回收策略persistentVolumeReclaimPolicy: Retain保留
该Retain回收政策允许资源的回收手册。当PersistentVolumeClaim删除时,PersistentVolume仍然存在,并且该卷被视为“已释放”。但它尚未提供另一项索赔,因为之前的索赔人的数据仍在数量上。管理员可以使用以下步骤手动回收卷。
- 删除PersistentVolume。删除PV后,外部基础架构(例如AWS EBS,GCEPD,Azure磁盘或Cinder卷)中的关联存储资产仍然存在。
- 相应地手动清理相关存储资产上的数据。
- 手动删除关联的存储资产,或者如果要重用同一存储资产,请PersistentVolume使用存储资产定义创建新的存储资产。
建立pv
1 | kubectl apply -f es-pv-api.yaml -f es-pv-node1.yaml -f es-pv-node2.yaml |
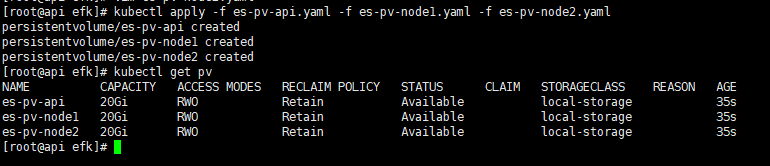
Elasticsearch安装
Elasticsearch最佳实践建议将节点分成三个角色:
- Master 节点 - 仅用于集群管理,无数据,无HTTP API
- Data 节点 - 用于客户端使用和数据
- Ingest 节点 - 用于摄取期间的文档预处理
1
2
3
4
5
6
7
8
9
10
11
12Master节点
es-master-discovery-svc.yaml
es-master-pdb.yaml
es-master-stateful.yaml
es-master-svc.yaml
Data节点
es-data-pdb.yaml
es-data-stateful.yaml
es-svc.yaml
Ingest 节点
es-ingest-deployment.yaml
es-ingest-svc.yaml
(非常)重要说明
- Elasticsearch pod需要init-container以特权模式运行,因此它可以设置一些VM选项。为此,kubelet应该使用args运行–allow-privileged,否则init-container将无法运行。
- 默认情况下,ES_JAVA_OPTS设置为-Xms256m -Xmx256m。这是一个非常低的值,但许多用户,即minikube用户,由于主机内存不足而导致pod被杀的问题。可以在此存储库中可用的部署描述符中更改此设置。此处我的data就修改为了1024m,如果报错,请根据日志信息(kubectllogs es-data-0 -n efk)获取的日志信息来进行调整。
- 目前,Kubernetes pod描述符emptyDir用于在每个数据节点容器中存储数据。这是为了简单起见,应根据一个人的存储需求进行调整。
- statefulset包含部署数据豆荚作为一个例子StatefulSet。这些使用一个volumeClaimTemplates为每个pod配置持久存储。此处已经说明了pv建立时模式是单节点的,所以可根据自己需求来进行调整两个statefulset的replicas数量(此处我是data1个 master 2个。)
- 默认情况下,PROCESSORS设置为1。对于某些部署,这可能是不够的,尤其是在启动时。根据需要调整resources.limits.cpu和或livenessProbe相应。请注意,resources.limits.cpu必须是整数。
- elasticsearch的服务端和访问的客户端版本必须一致,不然会导致elasticsearch服务停掉。列如我这里对应版本为常见问题
1
2
3
4elasticsearch:6.3.2
fluentd-elasticsearch:2.4.0
fluent-bit:0.13.2
kibana:6.3.2
为什么NUMBER_OF_MASTERS与master-replicas的数量不同?
- 之前master-replicas的数量是3,因为pv的模式问题,我修改为了2;
- 此环境变量的默认值为2,表示群集至少需要2个主节点才能运行。如果一个集群有3个主服务器并且有一个管理器死亡,则集群仍可正常工通常是最小主节点n/2 +1,其中n是群集中主节点的数量。如果一个集群有5个主节点,则一个节点应该至少有3个节点,小于该节点并且集群停止。如果缩放主数量,请确保通过Elasticsearch API更新主节点的最小数量,因为设置环境变量仅适用于群集设置。
检查是否成功建立
pv和pvc

pod

Clean-up with Curator
主要用于清理elasticsearch超过天数的数据,更多高级用法参考官方网站
https://www.elastic.co/guide/en/elasticsearch/client/curator/current/index.html
创建curator
使用到的yaml
1 | es-curator-configmap.yaml |
我们将其设置为一个定时任务,每天1点整进行清理超过3天的数据
Kibana
- Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。
- 你用Kibana来搜索,查看,并和存储在Elasticsearch索引中的数据进行交互。
- 你可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。
- Kibana使得理解大量数据变得很容易。它简单的、基于浏览器的界面使你能够快速创建和共享动态仪表板,实时显示Elasticsearch查询的变化。
使用到的yaml文件
1 | kibana-configmap.yaml |
kibana的汉化
kibana的汉化方式,已经放到了Docker目录下,也可以使用我已经汉化好的镜像
验证效果

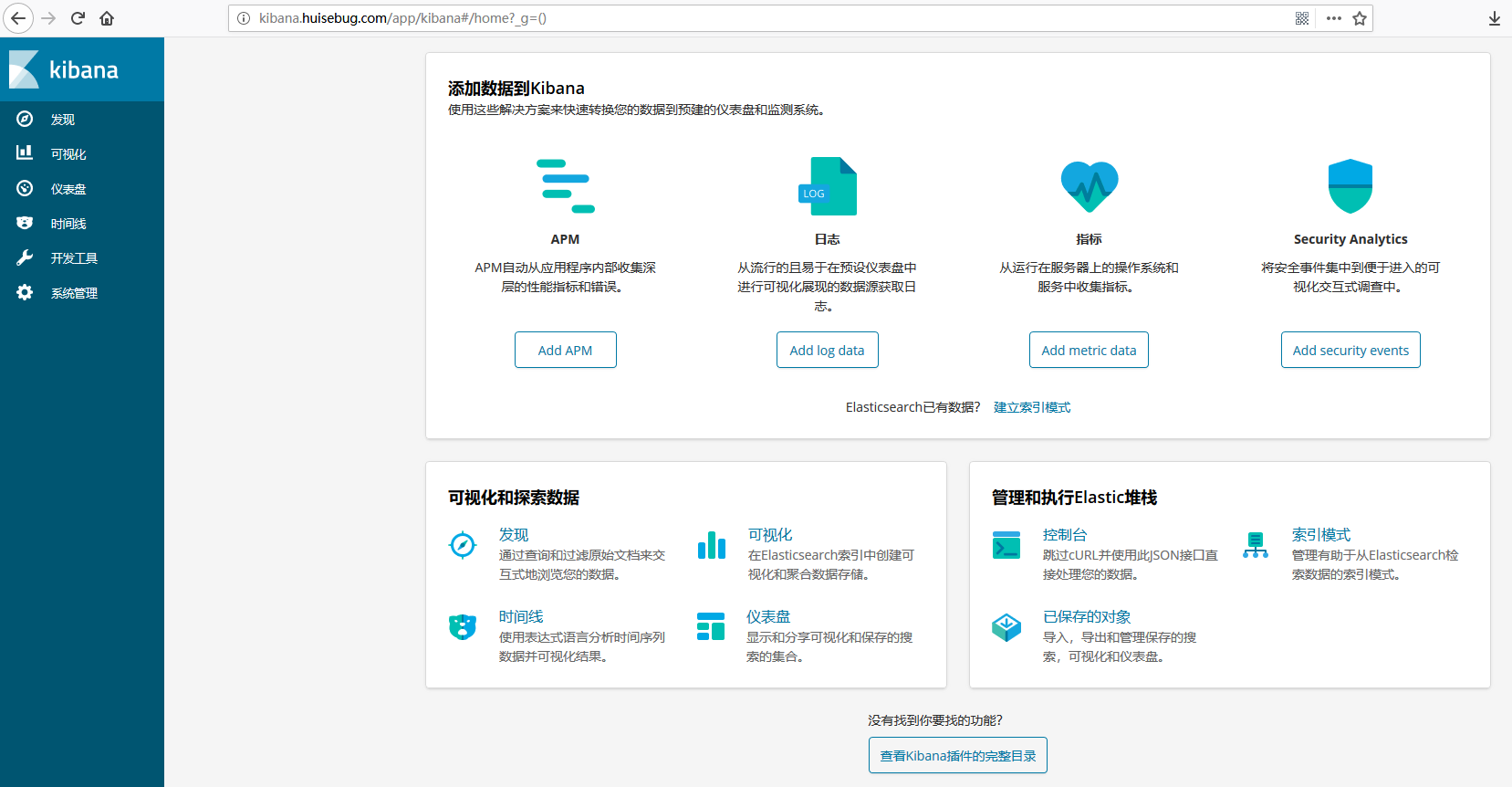
Fluent
| 组件 | 用途 |
|---|---|
| Fluent Bit | 拉起在每台宿主机上采集宿主机上的容器日志。(Fluent Bit 比较新一些,但是资源消耗比较低,性能比Fluentd好一些,但稳定性有待于进一步提升) |
| Fluentd | 两个用途:1 以日志收集中转中心角色拉起,Deployment部署模式;2 在部分Fluent Bit无法正常运行的主机上,以Daemon Set模式运行采集宿主机上的日志,并发送给日志收集中转中心 |
| ElasticSearch | 用来接收日志收集中转中心发送过来的日志,并通过Kibana分析展示出来,鉴于硬件资源有限,仅保留一周左右的数据。 |
| Amazon S3(fluentd server) | 用来接收日志收集中转中心发送过来的日志,对日志进行压缩归档,也可后续使用Spark进行进一步大数据分析。 |
fluentd直接传递es建立
此处我们演示fluentd直接向elasticsearch传递数据建立使用,使用到的yaml分别如下
fluentd
1 | fluentd-es-configmap.yaml |
给 Node 设置标签
定义fluentd-es-daemonset.yaml时设置了nodeSelector beta.kubernetes.io/fluentd-ds-ready=true,所以需要在期望运⾏fluentd 的 Node上设置该标签;
1 | for i in api.huisebug.com node1.huisebug.com node2.huisebug.com; do kubectl label nodes $i beta.kubernetes.io/fluentd-ds-ready=true; done |
我们这里是新建一个namespace:efk,所以建立fluentd-es-daemonset.yaml不能使用pod优先级priorityClassName:system-node-critical,需要注释掉。
查看是否成功建立
验证整个EFK效果
添加kibana检测到fluent传递给es的日志信息,并建立索引,如果整个集群没有建立成功,是不会自动出现如下界面的。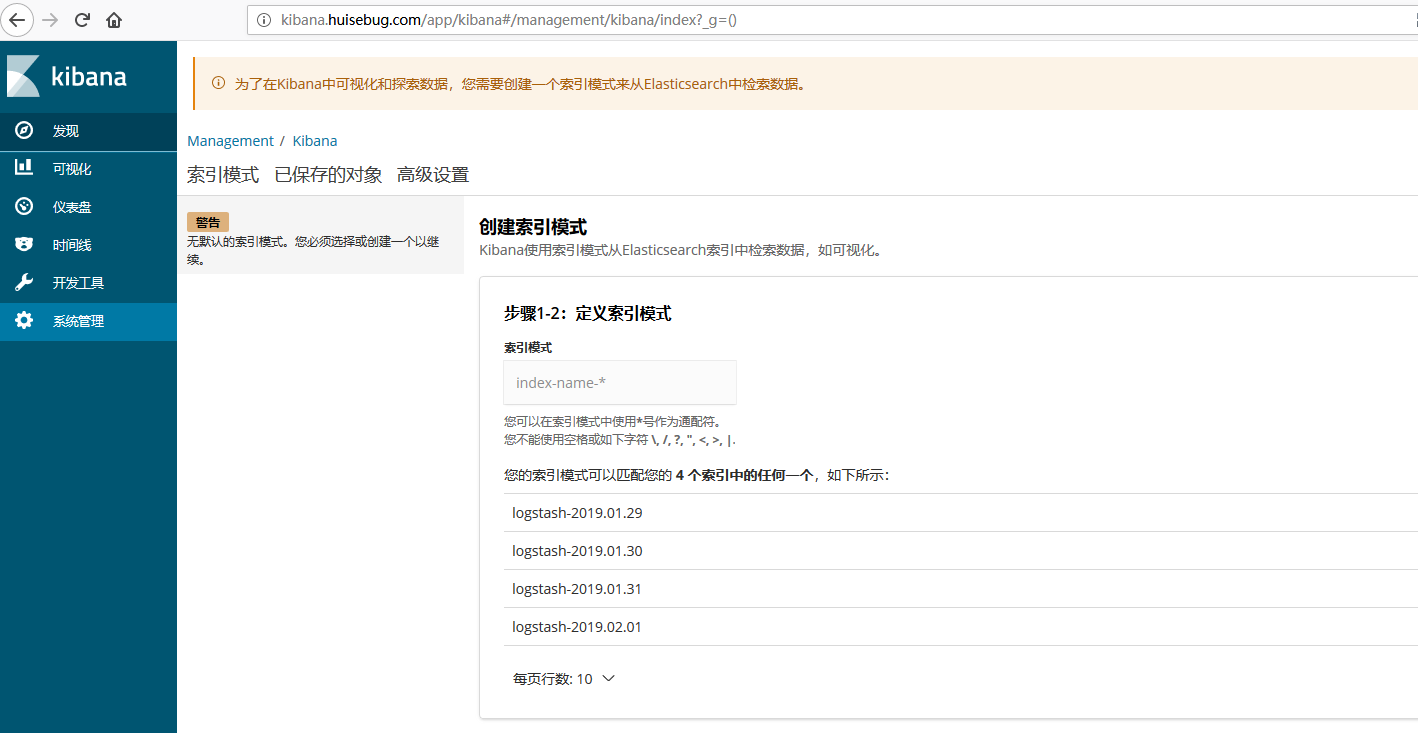
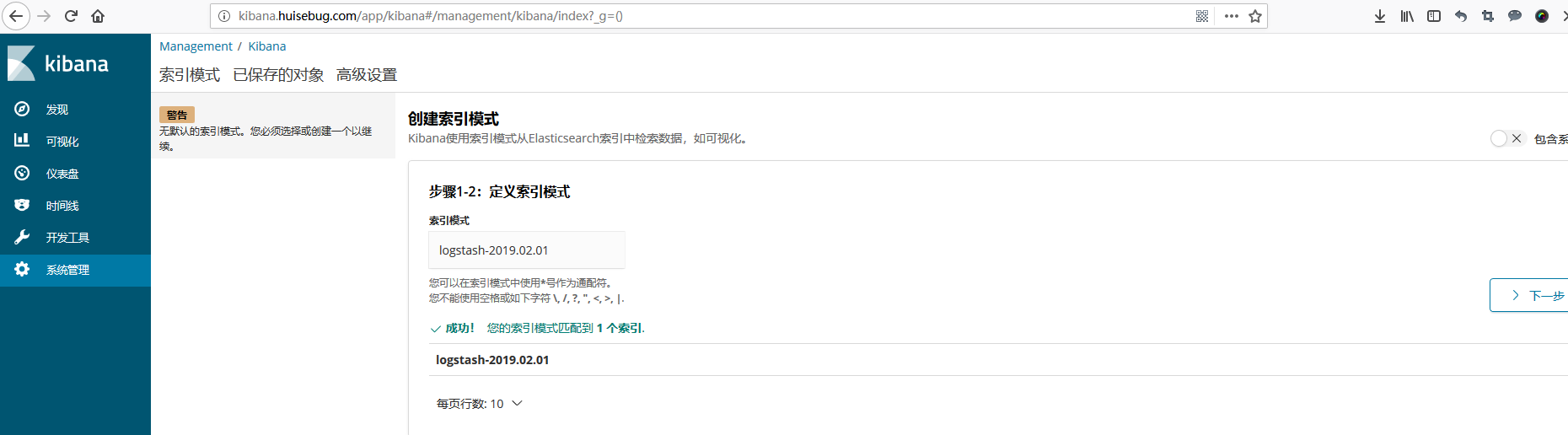
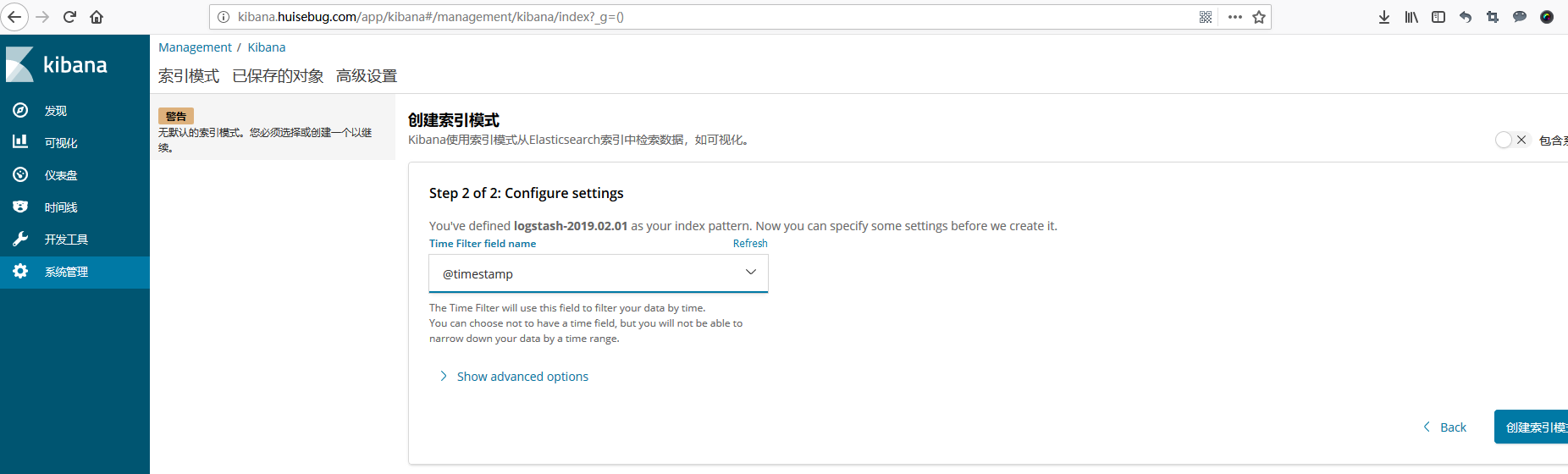
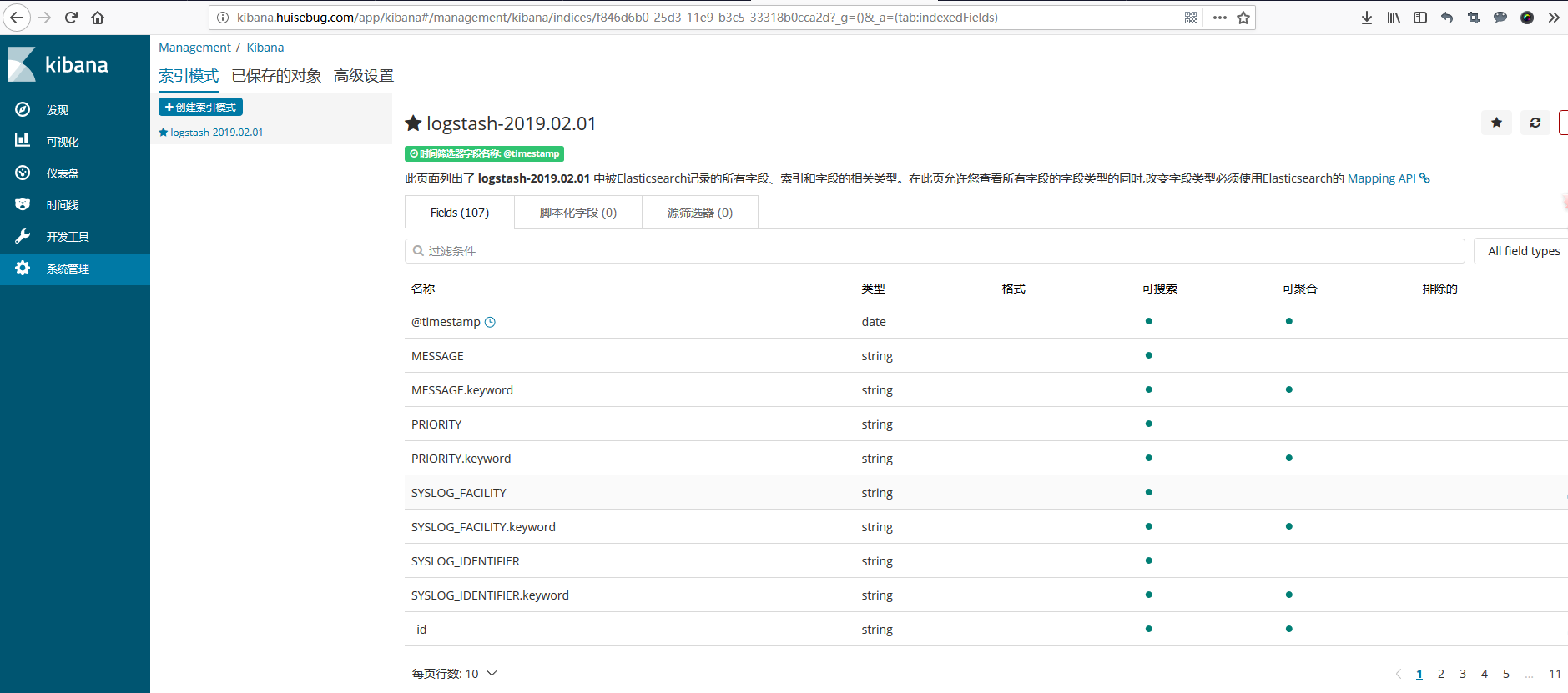
fluentd传递S3然后传递es
Amazon S3镜像建立
基于官方镜像添加对S3的支持,可在Docker目录下查找到Dockerfile,参考地址:
https://github.com/huisebug/EFK/blob/master/fluentd/Docker/Dockerfile
1 | FROM huisebug/sec_re:fluentd-elasticsearch-2.4.0 |
也可以直接使用我已经上传到dockerhub的镜像
使用到的yaml文件
fluentd
1 | fluentd-es-f-configmap.yaml |
S3
1 | fluentd-server-s3-configmap.yaml |
其中的fluentd-es-f-daemonset.yaml与之前的fluentd-es-daemonset.yaml内容相同,这里我为了便于区分。
fluentd-es-f-configmap.yaml 内容变更如下:
- 调整output.conf。
- 移除ES片段。
- 添加forward片段。
注意!!!
为了不影响测试效果,我们需要删除es建立的数据,并重新建立,切换到es的yaml文件所在目录
api.huisebug.com主机:
1 | kubectl delete -f . && rm -rf /data/* |
其余节点主机:
1 | rm -rf /data/* |
并且删除之前直接传递建立的fluentd
1 | kubectl delete -f fluentd-es-configmap.yaml -f fluentd-es-daemonset.yaml |
查看效果
访问kibana验证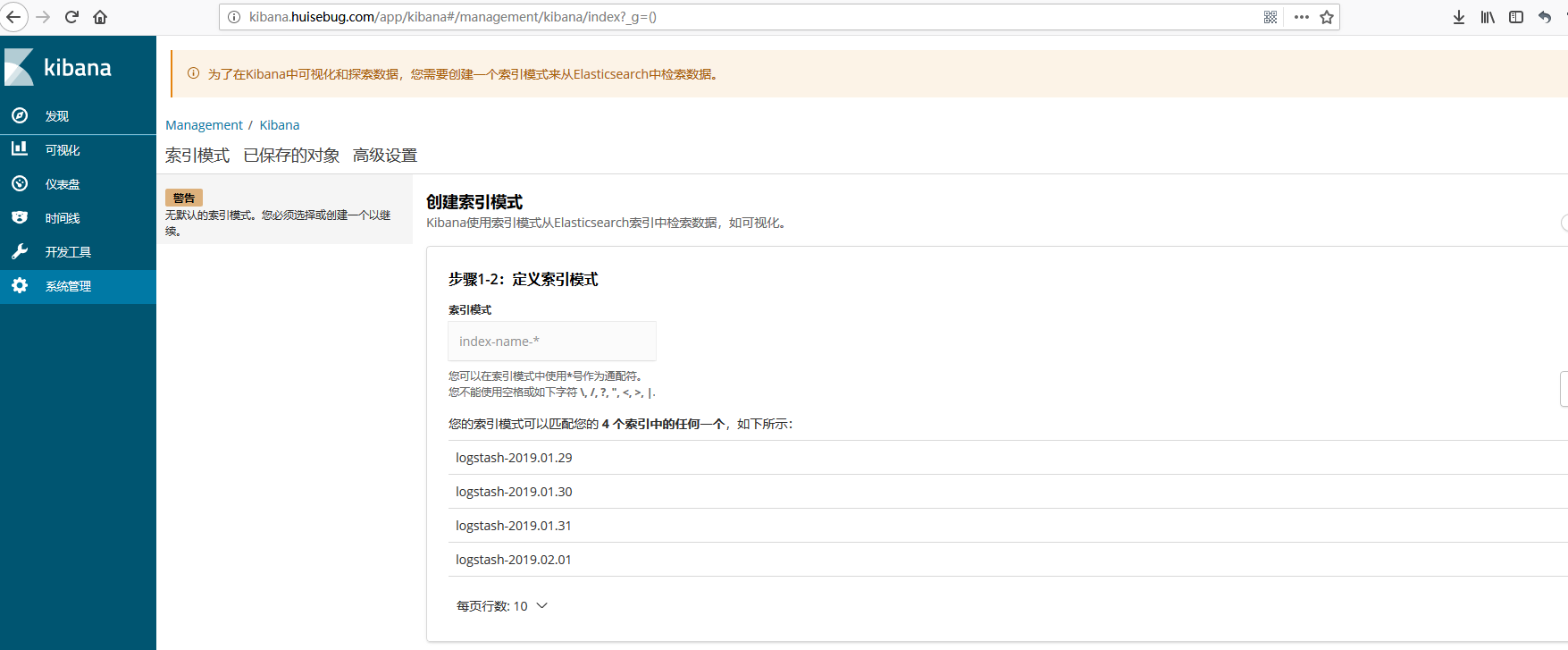
fluentd bit传递到S3然后传递es
使用到的yaml文件
fluentd-bit
1 | fluentd-bit-es-f-configmap.yaml |
S3
1 | fluentd-bit-server-s3-configmap.yaml |
其中的S3使用的yaml内容与之前的内容相同,这里我为了便于区分。
注意!!!
为了不影响测试效果,我们需要删除es建立的数据,并重新建立,切换到es的yaml文件所在目录
api.huisebug.com主机:
1 | kubectl delete -f . && rm -rf /data/* |
其余节点主机:
1 | rm -rf /data/* |
并且删除之前直接传递建立的fluentd-s3
1 | kubectl delete -f fluentd-es-f-configmap.yaml -f fluentd-es-f-daemonset.yaml |
查看效果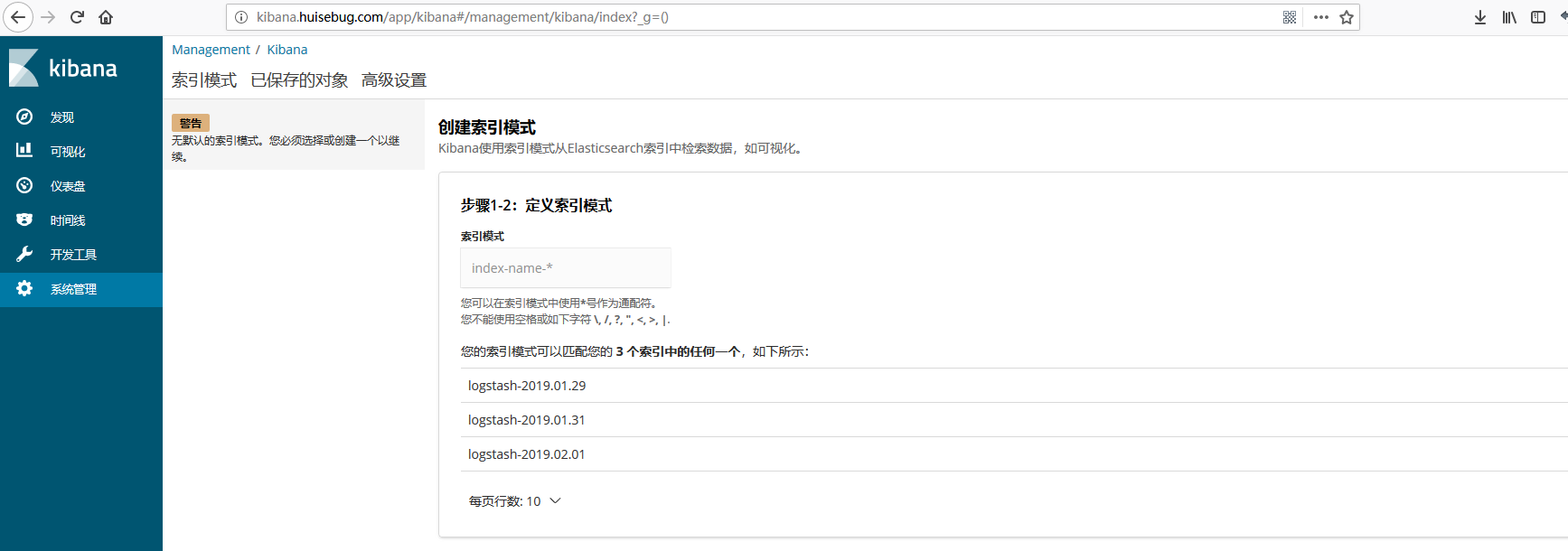
GlusterFS+Heketi+EFK
适用于生产环境
参考yaml文件
https://github.com/huisebug/GlusterFS-Heketi-EFK.git
三个文件夹,其他文件夹目录内容不变,这里主要需要修改ekheketi文件中的内容
ekheketi
将之前的ElasticSearch服务的三个角色分类文件目录存放,修改statefulset使用到的pvc的为storageClassName:
gluster-heketi,如下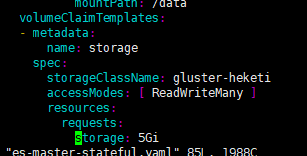
即可完成!!!
此处整个efk集群使用到pvc的有es-master和es-data。
搭建完成后查看是否成功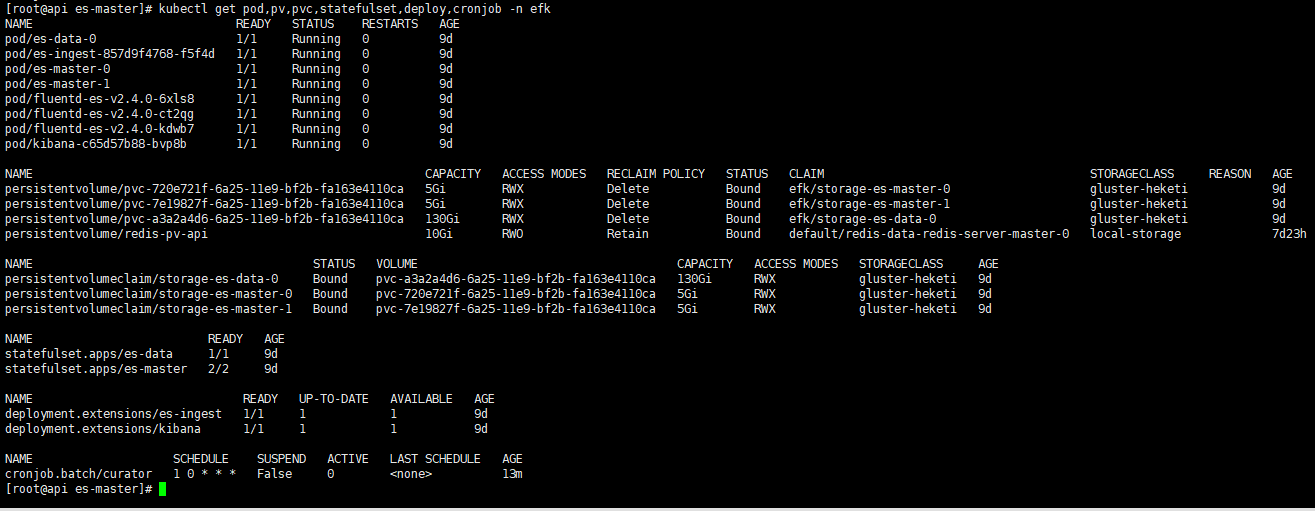
 wechat
wechat alipay
alipay







