
Kubernetes-hpav2横向自动扩容
这是一个k8s集群验证hpav2的功能
HPA
- Horizontal Pod Autoscaler根据观察到的CPU利用率自动调整复制控制器,部署或副本集中的pod数量(或者,使用自定义度量标准支持,根据其他一些应用程序提供的度量标准)。请注意,Horizontal PodAutoscaling不适用于无法缩放的对象,例如DaemonSet。
- Horizontal Pod Autoscaler实现为Kubernetes API资源和控制器。资源确定控制器的行为。控制器会定期调整复制控制器或部署中的副本数,以使观察到的平均CPU利用率与用户指定的目标相匹配
Horizontal Pod Autoscaler如何工作?
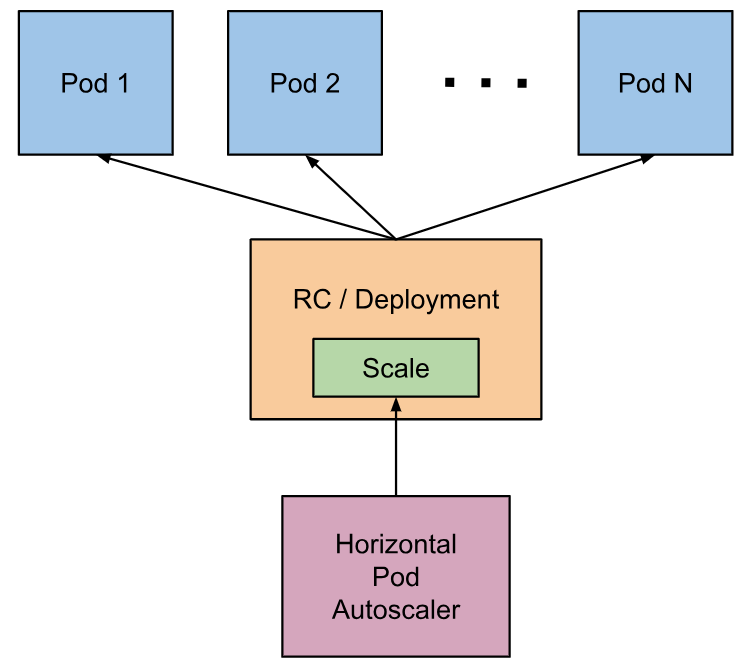
Horizontal Pod
Autoscaler实现为控制循环,其周期由控制器管理器的–horizontal-pod-autoscaler-sync-period标志控制(默认值为15秒)。
在每个期间,控制器管理器根据每个HorizontalPodAutoscaler定义中指定的度量查询资源利用率。控制器管理器从资源指标API(针对每个窗格资源指标)或自定义指标API(针对所有其他指标)获取指标。
- 对于每个pod资源指标(如CPU),控制器从HorizontalPodAutoscaler所针对的每个pod获取资源指标API中的指标。然后,如果设置了目标利用率值,则控制器将利用率值计算为每个容器中容器上的等效资源请求的百分比。如果设置了目标原始值,则直接使用原始度量标准值。然后,控制器在所有目标pod中获取利用率的平均值或原始值(取决于指定的目标类型),并产生用于缩放所需副本数量的比率。
请注意,如果某些pod的容器没有设置相关的资源请求,则不会定义pod的CPU利用率,并且autoscaler不会对该度量标准采取任何操作。有关自动调节算法如何工作的更多信息,请参阅下面的算法详细信息部分。 - 对于每个pod自定义指标,控制器的功能与每个pod资源指标类似,不同之处在于它适用于原始值,而不是使用值。
- 对于对象度量和外部度量,将获取单个度量,该度量描述相关对象。将该度量与目标值进行比较,以产生如上所述的比率。在autoscaling/v2beta2API版本中,可以选择在进行比较之前将此值除以pod的数量。
所述HorizontalPodAutoscaler通常由一系列的API聚集(的获取度量metrics.k8s.io,custom.metrics.k8s.io和external.metrics.k8s.io)。该metrics.k8s.ioAPI通常是通过度量服务器,其需要单独启动提供。有关说明,请参阅
metrics-server。HorizontalPodAutoscaler还可以直接从Heapster获取指标。
从Kubernetes 1.11开始,不推荐从Heapster获取指标。
算法细节
从最基本的角度来看,Horizontal Pod Autoscaler控制器根据所需度量值与当前度量值之间的比率进行操作:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
- 例如,如果当前度量标准值是200m,并且期望值是100m,则副本的数量将加倍,因为200.0 / 100.0 == 2.0如果当前值是50m,则我们将副本的数量减半,因为50.0 / 100.0 == 0.5。如果比率足够接近1.0(在全局可配置的容差范围内,从–horizontal-pod-autoscaler-tolerance标志,默认为0.1),我们将跳过缩放。
- 当指定a targetAverageValue或时targetAverageUtilization,currentMetricValue通过在HorizontalPodAutoscaler的比例目标中获取所有Pod的给定度量的平均值来计算。在检查容差和决定最终值之前,我们考虑了容量准备和缺失指标。
- 设置了删除时间戳的所有Pod(即正在关闭的Pod)和所有失败的Pod都将被丢弃。
- 如果特定的Pod缺少指标,则将其留待以后使用;具有缺失指标的窗格将用于调整最终缩放量。
- 在CPU上进行扩展时,如果任何pod尚未准备好(即它仍在初始化),或者pod的最新度量标准点在它准备就绪之前,那么该pod也会被搁置。
- 由于技术限制,在确定是否预留某些CPU指标时,HorizontalPodAutoscaler控制器无法准确确定容器第一次准备就绪。相反,它认为Pod尚未准备就绪,如果它尚未准备就绪,并且在它启动后的一个简短,可配置的时间窗口内转换为未准备好。此值使用–horizontal-pod-autoscaler-initial-readiness-delay标志配置,默认值为30秒。一旦pod准备就绪,它会认为任何转换都准备好成为第一个,如果它在启动后的较长的可配置时间内发生的话。此值使用–horizontal-pod-autoscaler-cpu-initialization-period标志配置,默认值为5分钟。
- 所述currentMetricValue / desiredMetricValue然后碱比例是利用剩余的pod没有预留或从上方丢弃计算。
- 如果有任何缺失的指标,我们会更加保守地重新计算平均值,假设这些容量在缩小的情况下消耗100%的期望值,并且在放大的情况下消耗0%。这可以抑制任何潜在规模的大小。
- 此外,如果存在任何尚未准备好的播客,并且我们会扩大规模而不考虑丢失的指标或尚未准备好的播客,我们保守地假设尚未准备好的播客正在消耗所需指标的0%,进一步抑制了规模扩大的程度。
- 考虑到尚未准备好的广告连播和缺少指标后,我们会重新计算使用率。如果新比率反转了比例方向,或者在公差范围内,我们会跳过缩放比例。否则,我们使用新的比例进行扩展。
- 请注意,即使使用新的使用率,也会通过HorizontalPodAutoscaler状态报告平均利用率的原始值,而不考虑尚未准备好的容器或缺少指标。
- 如果在HorizontalPodAutoscaler中指定了多个度量标准,则对每个度量标准进行此计算,然后选择所需的最大副本计数。如果任何这些度量标准无法转换为所需的副本计数(例如,由于从度量标准API获取度量标准时出错),则会跳过缩放。
- 最后,在HPA扩展目标之前,记录比例建议。控制器会在可配置窗口中考虑所有建议,从该窗口中选择最高建议。可以使用–horizontal-pod-autoscaler-downscale-stabilization-window标志配置此值,默认为5分钟。这意味着缩放将逐渐发生,平滑快速波动的度量值的影响。
使用Horizontal Pod自动缩放器管理一组副本的比例时,由于所评估的度量标准的动态特性,副本数量可能会不断波动。这有时被称为颠簸。
从v1.6开始,集群运营商可以通过调整作为kube-controller-manager组件标志公开的全局HPA设置来缓解此问题:
从v1.12开始,新的算法更新消除了对高级延迟的需求。
–horizontal-pod-autoscaler-downscale-delay:此选项的值是一个持续时间,指定自动缩放器必须等待多长时间才能在当前完成后执行另一个缩减操作。默认值为5分钟(5m0s)。
注意:调整这些参数值时,集群操作员应了解可能的后果。如果延迟(冷却)值设置得太长,可能会有人抱怨Horizontal Pod Autoscaler没有响应工作负载变化。但是,如果延迟值设置得太短,副本集的比例可能会像往常一样保持颠簸。
支持的API
默认情况下,HorizontalPodAutoscaler控制器从一系列API中检索指标。为了使其能够访问这些API,集群管理员必须确保:
1.该API汇聚层启用。
2.相应的API已注册:
- 对于资源指标,这是metrics.k8s.ioAPI,通常由metrics-server提供。它可以作为群集插件启动。
- 对于自定义指标,这是custom.metrics.k8s.ioAPI。它由度量标准解决方案供应商提供的“适配器”API服务器提供。检查您的指标管道或已知解决方案列表。如果您想自己编写,请查看样板文件以开始使用。
- 对于外部指标,这是external.metrics.k8s.ioAPI。它可能由上面提供的自定义指标适配器提供。
3.–horizontal-pod-autoscaler-use-rest-clients=true已经在1.12+版本取消。将此设置为false会切换到基于Heapster的自动缩放,不推荐使用。
官方参考文档链接地址:
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
HPA V1
v2已经集成v1的功能,所以这里就不演示v1了。
最简易的v1,例如下面命令或者yaml示例
1 | kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=103 |
HPA V2
下面是之前提到的版本问题HPA无法获取内存情况
参考地址:
https://github.com/kubernetes/kubernetes/issues/74704
k8s从v1.7版本开始,对支持自定义指标的HPA架构进行了重新设计,引入了api server aggregation层、custom metrics server等组件来实现自定义业务指标的采集、保存和查询、再提供给HPA控制器进行扩缩容决策,称为HPA V2版本;
首先我们需要给kube-controller-manager服务增加三个参数:
1 | --horizontal-pod-autoscaler-sync-period=30s \ |
分别是同步时间,缩容时间,扩容时间
参考修改后的kube-controller-manager服务service文件地址:
https://github.com/huisebug/k8s1.12-Ecosphere/tree/master/hpav2/kube-controller-manager
概念解析
- cluster-autoscaler:kubernetes社区中负责节点水平伸缩的组件,目前处在GA阶段(General Availability,即正式发布的版本)。
- HPA:kubernetes社区中负责Pod水平伸缩的组件,是所有伸缩组件中历史最悠久的,目前支持autoscaling/v1、autoscaling/v2beta1与autoscaling/v2beta2,其中autoscaling/v1只支持CPU一种伸缩指标,在autoscaling/v2beta1中增加支持custommetrics,在autoscaling/v2beta2中增加支持external metrics。(获取命令kubectlapi-versions)
- cluster-proportional-autoscaler:根据集群的节点数目,水平调整Pod数目的组件,目前处在GA阶段。
- vetical-pod-autoscaler:根据Pod的资源利用率、历史数据、异常事件,来动态调整负载的Request值的组件,主要关注在有状态服务、单体应用的资源伸缩场景,目前处在beta阶段。
- addon-resizer:根据集群中节点的数目,纵向调整负载的Request的组件,目前处在beta阶段。
Resouce类型(CPU、内存)
运行原理简析
扩容
spec.template.spec.containers.resources.requests来为基数,
根据pod消耗的cpu数量相加求出平均值,然后除以基数,即可得到当前百分比(current),超出设置的目标百分比(target)就进行扩容,低于就缩容。

内存根据pod消耗的内存值相加求出平均值就是当前值(current),与目标值(target)相比较,高于就扩容。
缩容
如果是CPU的原因进行了扩容后,CPU消耗百分比低于目标百分比将会进行缩容,此时平均消耗内存除以目标值,如果接近于1就不进行完全的缩容。
实践探究
部署mysql-rc服务
yaml文件参考地址:
https://github.com/huisebug/k8s1.12-Ecosphere/tree/master/hpav2/mysql-rc
注意,使用hpav2的type: Resource,必须在pod中定义spec.template.spec.containers.resource,否则没有具体的基数。
1 | apiVersion: v1 |
1 | apiVersion: autoscaling/v2beta1 |
| 指示 | 描述 |
| apiVersion: autoscaling/v2beta1 | autoscaling正在使用的Kubernetes API组的版本。此示例清单使用beta版本,因此启用了按CPU和内存进行扩展。 |
| name: mysql-rc | 表示HPA正在为mysql-rc部署执行自动扩展。 |
| minReplicas: 1 | 表示运行的最小副本数不能低于1。 |
| maxReplicas: 3 | 表示部署中最大副本数不能超过3。 |
| targetAverageUtilization: 80 | 表示当平均运行pod使用超过其请求CPU的80%时,部署将扩展pod。 |
| targetAverageValue: 1300Mi | 表示当平均运行pod使用超过1300Mi的内存时,部署将扩展pod。
验证效果
部署结果
1 | kubectl get pod -l name=mysql-pod |

CPU扩容
进入pod中的容器
1 | kubectl exec -it mysql-rc-9ngzn bash |
使CPU满载
1 | for i in `seq 1 $(cat /proc/cpuinfo |grep "physical id" |wc -l)`; do dd if=/dev/zero of=/dev/null & done |

查看扩容情况,之前设定了扩容间隔时间(–horizontal-pod-autoscaler-upscale-delay=3m0s)为3m0s。所以我们需要等待大约3分钟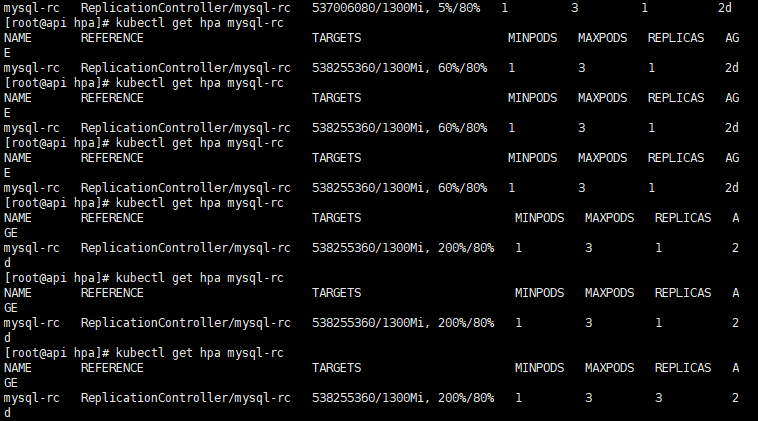
CPU缩容
杀死容器进程1,即会重启容器,然后增压CPU的循环将会停止,以达到CPU的负载就会将下来,然后进行缩容。
内存不影响的情况下
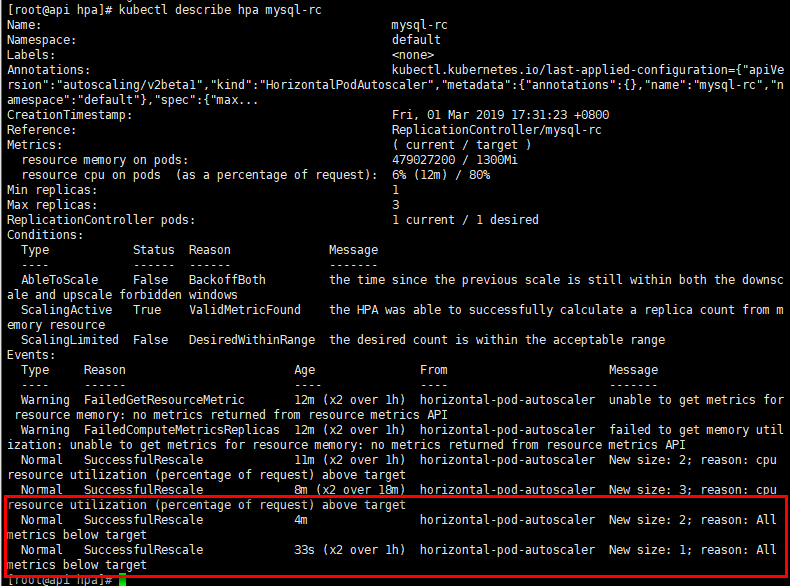
内存影响情况下
此处的mysql稳定运行消耗的内存为500Mi左右,为了让其缩容比例接近于1,以达到扩容后,就算CPU消耗降下来,因为内存的current/target接近于1,不会完全的缩容到最小副本数。
参考yaml文件
1 | kubectl delete hpa mysql-rc |
测试步骤和上面一样




此时pod数量将会缩减为2,所以目标值的设定可以经过实际场景数据进行分析。
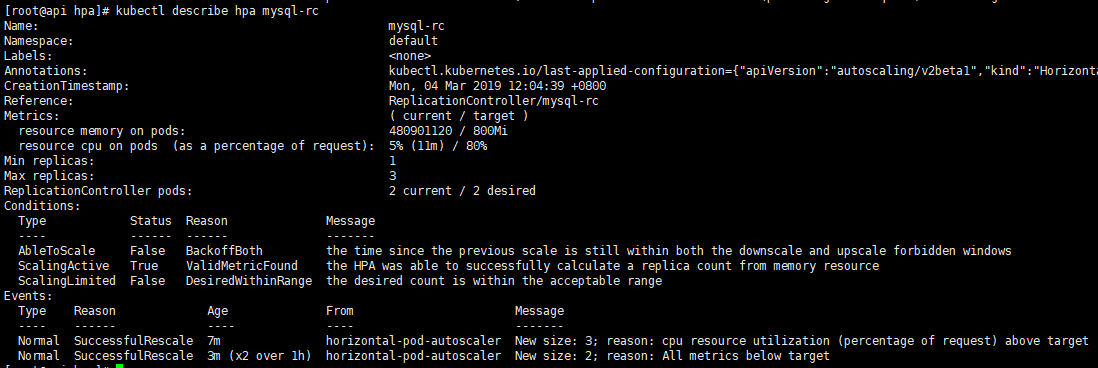
建立custom.metrics.k8s.io
使用HPA v2的type为Resource时,使用的api是metrics.k8s.io,这个是由metrics-server提供的,使用type为Pods和Object时就需要使用的api是custom.metrics.k8s.io;
其中的Custom Metrics Server由prometheus-adapter服务实现,这个服务在之前我们安装prometheus-operator服务的时候已经安装。但是其安装的是api:metrics.k8s.io,并且其功能并不满足。所以在metrics-server1.12已经将api:metrics.k8s.io移除并使用metrics-server来提供支持。并且移除了prometheus-adapter服务。
github上有位大神的方法可以成功,参考地址如下,并且里面也有metrics-server的安装和验证
1 | git clone https://github.com/stefanprodan/k8s-prom-hpa |
需要修改镜像地址为可拉取的,可参考我修改了的
https://github.com/huisebug/k8s1.12-Ecosphere/tree/master/hpav2/k8s-prom-hpa
部署Prometheus和Prometheus-adapter
创建monitoring命名空间:
1 | kubectl create -f ./namespaces.yaml |
在monitoring命名空间中部署Prometheus v2 :
如果要部署到GKE,可能会收到错误消息:Error from server (Forbidden): error when
creating 这将帮助您解决该问题:GKE上的RBAC
1 | kubectl create -f ./prometheus |
生成Prometheus适配器所需的TLS证书:
1 | make certs |
部署Prometheus自定义指标API适配器:
1 | kubectl create -f ./custom-metrics-api |
验证并访问api
查看pod是否成功建立

1 | kubectl api-versions | grep custom.metrics.k8s.io |

安装jQuery插件,并将请求值转换为json
1 | yum install epel-release |
获取monitoring命名空间中所有pod的FS使用情况:
1 | kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq . |
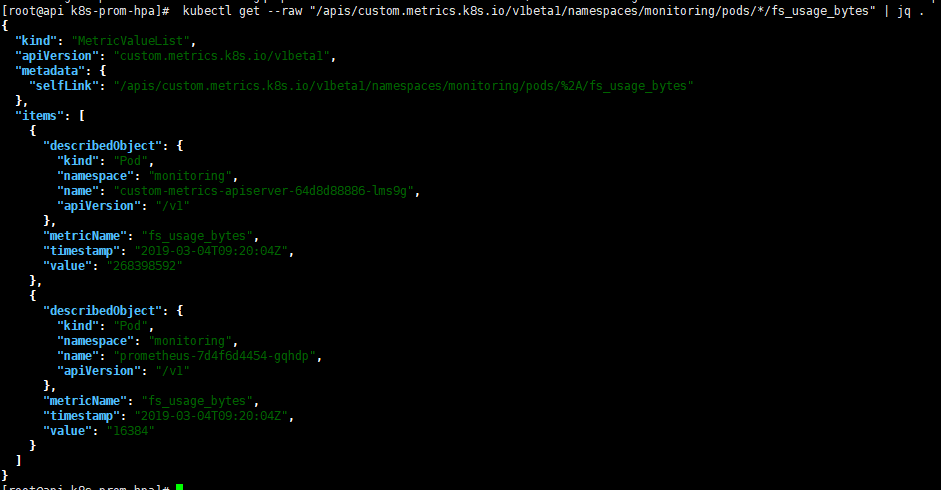
Pods类型
创建Pod
依照项目k8s-prom-hpa中的podinfo文件目录下来验证。
podinfo在default命名空间中创建NodePort服务和部署
1 | kubectl create -f ./podinfo/podinfo-svc.yaml ./podinfo/podinfo-dep.yaml |
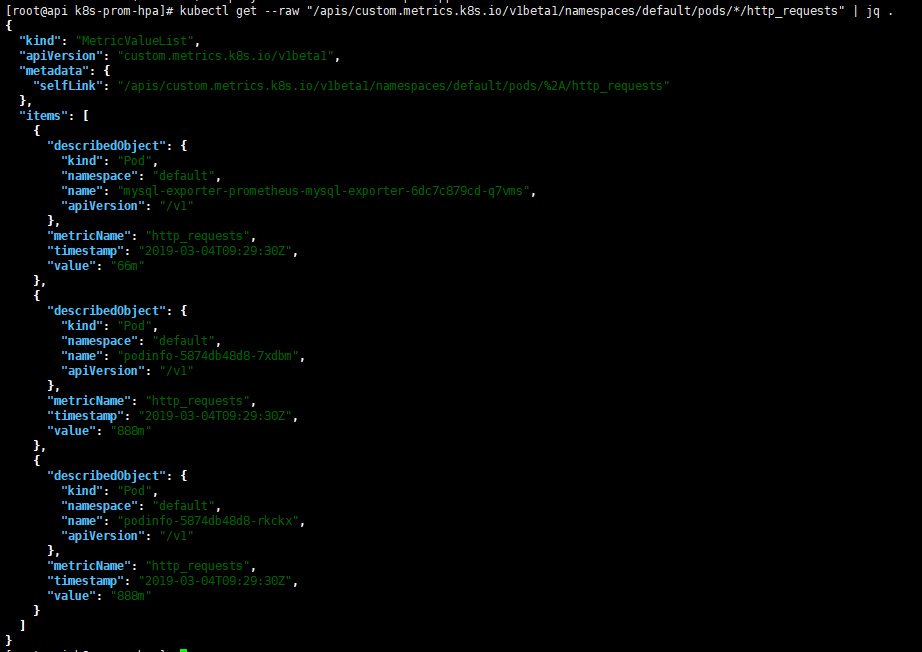
该podinfo应用程序公开名为的自定义指标http_requests_total。Prometheus适配器删除_total后缀并将度量标记为计数器度量标准。
从自定义指标API获取每秒的总请求数:
1 | kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq . |
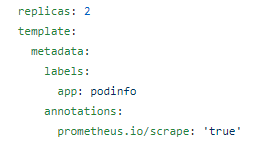
注意:如果想让prometheus从pod抓取数据,需要在template声明annotations:中添加 prometheus.io/scrape: ‘true’
创建HPA
podinfo如果请求数超过每秒10个,将扩展部署
podinfo在default命名空间中部署HPA
1 | kubectl apply -f ./podinfo/podinfo-hpa-custom.yaml |

注意:不加m的时候,单位的默认是n1000m,即上面是101000m=10000m
安装 hey 压力测试工具
1 | docker run -dit -v /usr/local/bin:/go/bin golang:1.8 go get github.com/rakyll/hey |
执行请求测试后,可以看到pod数量变为了3

增大请求,pod数量变成4,停止后等待大约3分钟就可以缩容到最小副本数
1 | hey -n 50000 -q 5 -c 5 |


Object类型
可支持的数据来源可以是service、endpoint等。
暂时无法实现,分析原因是需要在prometheus-adapter的配置文件中定义service,因为prometheus可以在service中声明annotations:中添加
prometheus.io/scrape: ‘true’
是可以获取到的metrics的,可是在api就无法访问到。
参考yaml:
https://github.com/huisebug/k8s1.12-Ecosphere/tree/master/hpav2/sample-metrics
失败
部署prometheus
参考我的values-hpav2.yaml文件地址:
https://github.com/huisebug/k8s1.12-Ecosphere/tree/master/hpav2/prometheus
1 | helm delete prometheushpa --purge |
部署的服务如下:
- 关闭告警插件alertmanager
- 关闭节点收集器nodeexporter
- 关闭网关pushgateway
- 开启deployment收集器kubestatemetrics
- 开启prometheus
注意:我为方便与prometheus-operator安装prometheus区分,将服务命名为prometheushpa
部署prometheus-adapter
参考我的values-hpav2.yaml文件地址:
https://github.com/huisebug/k8s1.12-Ecosphere/tree/master/hpav2/prometheus-adapter
1 | helm delete prometheus-adapter --purge |
注意:prometheus-adapter去连接prometheushpa时,helm方式安装的prometheus的service port是80,不是9090;当然你可以修改为9090
 wechat
wechat alipay
alipay






