这是一个k8s集群,从零开始搭建服务器环境,keepalived+haproxy实现集群高可用VIP;glusterfs搭建实现可持续存储;k8s1.12版本集群;efk日志系统;prometheus-operator告警系统;HPA v2横向pod扩容;k8s1.11+以上的版本部署基本没什么区别,无非就是优化了一些参数的配置和增加一些功能,舍弃一些api,此文档适用后续发布的其他版本的部署,提供一些部署思路。
硬件环境准备
服务器三台centos7.6
每台服务器两块硬盘,一块作为服务器硬盘,一块作为glusterFS硬盘
关闭firewalld防火墙和selinux
IP地址:192.168.137.10—12/24;主机名api、node1、node2.huisebug.com
使用阿里云yum源
下面的操作是之前使用k8s1.12.4搭建的,其中的参数同样适用于k8s.12.*,因为hpa的原因替换为了k8s1.11.8。
k8s版本1.11.8(2019年3月1号发布);
hpa在如下版本会会存在hpa无法获取内存的使用情况的bug,所以不推荐使用这些版本,其他版本未测试。如果你在使用了1.11.*版本后切换到了如下版本,是因为数据在etcd还没更新,一段时间后就会提示获取不到
k8s1.13.3
总结出k8s1.12+版本的HPA是无法获取内存使用情况,进一步跟进官方,k8s1.11.*版本是不支持autoscaling/v2beta2.
进行系统配置并开启IPVS
关闭防火墙、selinux
关闭系统的Swap,Kubernetes 1.8开始要求。
关闭linux swap空间的swappiness
配置L2网桥在转发包时会被iptables的FORWARD规则所过滤,该配置被CNI插件需要,更多信息请参考NetworkPluginRequirements
开启IPVS,将会后续应用到kube-proxy中去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # 所有主机:基本系统配置 # 关闭Selinux/firewalld systemctl stop firewalld systemctl disable firewalld setenforce 0 sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config # 关闭交换分区 swapoff -a yes | cp /etc/fstab /etc/fstab_bak cat /etc/fstab_bak |grep -v swap > /etc/fstab # 增加个谷歌dns,方便访问外网 echo "nameserver 8.8.8.8" >> /etc/resolv.conf # 设置网桥包经IPTables,core文件生成路径 echo """ vm.swappiness = 0 vm.overcommit_memory=1 vm.panic_on_oom=0 """ > /etc/sysctl.conf modprobe br_netfilter sysctl -p
从Linux内核3.18-rc1开始,你必须使用modprobe br_netfilter来启用bridge-netfilter。,不然会提示以下错误
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 # 所有主机:基本系统配置 # 同步时间 yum install -y ntpdate ntpdate -u ntp.api.bz # 安装内核组件 rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm ;yum --enablerepo=elrepo-kernel install kernel-lt-devel kernel-lt -y # 检查默认内核版本高于4.1,否则请调整默认启动参数 grub2-editenv list # 确认内核版本 uname -a 注解:一般centos7的内核是3.10.当你升级后重启服务器,显示的内核还是之前的,因为你没切换到新内核,需要在主机启动页面选择,如果是云服务器,是看不到选择界面的,这时候就需要将新安装的内核设定为操作系统的默认内核,或者说如何将新版本的内核设置为重启后的默认内核? 仅需两步,之后重启即可。 grub2-set-default 0 grub2-mkconfig -o /etc/grub2.cfg reboot # 重启后再次执行以下命令,确认内核版本 uname –a # 确认内核高于4.1后,开启IPVS cat > /etc/sysconfig/modules/ipvs.modules <<EOF # !/bin/bash ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack_ipv4" for kernel_module in \${ipvs_modules}; do /sbin/modinfo -F filename \${kernel_module} > /dev/null 2>&1 if [ \$? -eq 0 ]; then /sbin/modprobe \${kernel_module} fi done EOF # 授权并执行 chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs
Kubernetes要求集群中所有机器具有不同的Mac地址、产品uuid、Hostname。可以使用如下命令查看Mac和uuid
1 2 3 # 所有主机:检查UUID和Mac cat /sys/class/dmi/id/product_uuid ip link
GlusterFS 搭建glusterfs来作为可持续存储k8s的CSI(可以跳过不部署)
安装glusterfs 三台服务器都要执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 先安装 gluster 源 $ yum install centos-release-gluster -y # 安装 glusterfs 组件(这里包含了server和client) $ yum install -y glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma glusterfs-geo-replication glusterfs-devel # 创建 glusterfs服务运行目录 $ mkdir /opt/glusterd # 修改 glusterd 目录,将/var/lib改成/opt $ sed -i & # 启动 glusterfs(为挂载提供服务) $ systemctl start glusterd.service # 设置开机启动 $ systemctl enable glusterd.service # 查看状态 $ systemctl status glusterd.service
配置 glusterfs 三台服务器都要执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 # 配置本地解析文件hosts $ vi /etc/hosts 192.168.137.10 api.huisebug.com 192.168.137.11 node1.huisebug.com 192.168.137.12 node2.huisebug.com # 开放端口(24007是gluster服务运行所需的端口号)如果关闭了防火墙就省略此步操作。 $ iptables -I INPUT -p tcp --dport 24007 -j ACCEPT # 创建存储目录 $ mkdir /opt/gfs_data 为了方便管理可使用一块新硬盘新建一个分区将其挂载到 /opt/gfs_data # 查看硬盘 $ fdisk -l /dev/sdb # 建立分区并格式化为xfs类型 $ fdisk /dev/sdb 1. n 建立新分区 2. p 建立主分区 3. 1 分区号为1 4. 一直回车默认,将整块磁盘建立为一个分区,使用全部空间 5. w 保存退出 # 使分区生效 $ partprobe /dev/sdb # 强制格式化为xfs $ mkfs.xfs -f /dev/sdb1 # 手动将/dev/sdb1分区挂载到/opt/gfs_data $ mount /dev/sdb1 /opt/gfs_data # 开机自动挂载 $ echo "/dev/sdb1 /opt/gfs_data xfs defaults 0 0" >> /etc/fstab # 查看挂载状态 $ df –hT
添加节点到集群 三台服务器都安装好服务并成功启动后
执行probe操作即将三台服务器的gluster服务建立集群,选择其中任意一台执行probe操作,将会建立一个集群,执行完成后在任意一台执行以下命令
将会看到其他两台的信息
1 2 gluster peer probe node1.huisebug.com gluster peer probe node2.huisebug.com
查看状态
volume 类型 GlusterFS中的volume的模式有很多中,包括以下⼏种:
分布卷(默认模式):即DHT, 也叫 分布卷: 将⽂件已hash算法随机分布到⼀台服务器节点中存储。
复制模式:即AFR, 创建volume 时带 replica x 数量: 将⽂件复制到replica x个节点中。
条带模式:即Striped, 创建volume 时带 stripe x 数量:将⽂件切割成数据块,分别存储到 stripe x 个节点中 ( 类似raid 0 )。
分布式条带模式:最少需要4台服务器才能创建。 创建volume 时stripe 2 server = 4个节点: 是DHT 与 Striped 的组合型。
分布式复制模式:最少需要4台服务器才能创建。 创建volume 时replica 2 server =4 个节点:是DHT 与 AFR 的组合型。
条带复制卷模式:最少需要4台服务器才能创建。 创建volume 时stripe 2 replica 2 server = 4 个节点: 是 Striped 与 AFR 的组合型。
三种模式混合: ⾄少需要8台 服务器才能创建。 stripe 2 replica 2 ,每4个节点组成⼀个组。http://www.cnblogs.com/jicki/p/5801712.html
为了项目要求,我这里建立复制模式的volume
建立复制卷 现在整个gluster集群是一个整体,任意节点执行都可以
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 建立复制卷,卷名为test-volume $ gluster volume create test-volume replica 3 \ api.huisebug.com:/opt/gfs_data \ node1.huisebug.com:/opt/gfs_data \ node2.huisebug.com:/opt/gfs_data \ force # 开启复制卷 $ gluster volume start test-volume # 查看volume状态 $ gluster volume info Volume Name: test-volume <br>Type: Replicate <br>Volume ID: b52e2b36-0a88-43c5-b596-5ec0e01ca529 <br>Status: Started <br>Snapshot Count: 0 <br>Number of Bricks: 1 x 3 = 3<br> Transport-type: tcp <br>Bricks: <br>Brick1: api.huisebug.com:/opt/gfs_data <br>Brick2: node1.huisebug.com:/opt/gfs_data <br>Brick3: node2.huisebug.com:/opt/gfs_data <br>Options Reconfigured: <br>transport.address-family: inet <br>nfs.disable: on <br>performance.client-io-threads: off
配额限制 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # 开启 指定 volume 的配额 $ gluster volume quota test-volume enable # 限制 指定 volume 的配额,我们这里的硬盘是50G,所以分配给他10G $ gluster volume quota test-volume limit-usage / 10GB # 设置 cache ⼤⼩, 默认32MB,这个千万别设置太大了,不然会导致挂载不上 $ gluster volume set test-volume performance.cache-size 160MB # 设置 io 线程, 太⼤会导致进程崩溃 $ gluster volume set test-volume performance.io-thread-count 16 # 设置 ⽹络检测时间, 默认42s $ gluster volume set test-volume network.ping-timeout 10 # 设置 写缓冲区的⼤⼩, 默认1M $ gluster volume set test-volume performance.write-behind-window-size 1024MB # 设置 回写 (写数据时间,先写入缓存内,再写入硬盘) $ gluster volume set test-volume performance.write-behind on # 设置好了voleme的配额后要重新启动卷 $ gluster volume stop test-volume $ gluster volume start test-volume
挂载使用 三台服务器都要执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 建立使用服务器的目录 $ mkdir -p /opt/gfs_datause # 挂载关联 mount –t 指定挂载的卷类型 主机地址:卷名 挂载到本地的哪个目录(主机地址输入哪台服务器的地址都可以) $ mount -t glusterfs api.huisebug.com:test-volume /opt/gfs_datause 如果挂载失败,查看日志文件/var/log/glusterfs/opt-gfs_datause.log解决问题所在,我遇到是我把gluster volume set test-volume performance.cache-size 160MB设置为了4GB,导致无法挂载,然后我修改为了160MB,就可以了 # 查看挂载情况,如果要持续使用记得设置自动挂载 $ df -hT 文件系统 类型 容量 已用 可用 已用% 挂载点 api.huisebug.com:test-volume fuse.glusterfs 10G 0 10G 0% /opt/gfs_datause # 自动挂载 echo "api.huisebug.com:test-volume /opt/gfs_datause glusterfs defaults 0 0" >> /etc/fstab
记得执行node1和node2上述操作
测试同步效果 1 2 3 4 5 6 7 8 9 [root@api gfs_datause]# touch {1..10} [root@api gfs_datause]# ls 1 10 2 3 4 5 6 7 8 9 [root@node1 opt]# ls gfs_datause/ 1 10 2 3 4 5 6 7 8 9 [root@node2 gfs_datause]# ls 1 10 2 3 4 5 6 7 8 9
GlusterFS搭建完毕!!!
Keepalived 整个集群的高可用VIP
三台服务器都要执行
1 2 # 安装keepalived和ipvs、socat $ yum install -y socat keepalived ipvsadm
启动Keepalived服务 修改配置文件keepalived.conf为如下三台服务器的,这里我们暂时先让VIP运行起来,后续监听端口和进程后续再增加。
api
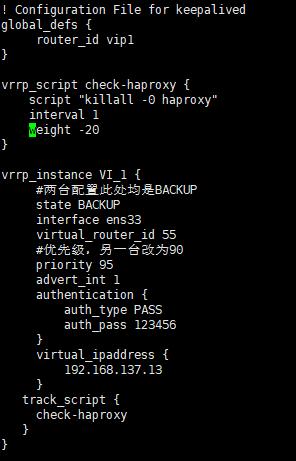
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 $ vim /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id vip1 } vrrp_instance VI_1 { # 三台配置此处均是BACKUP state BACKUP interface ens33 virtual_router_id 55 # 优先级 priority 95 advert_int 1 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 192.168.137.13 } }
node1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 $ vim /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id vip2 } vrrp_instance VI_1 { # 三台配置此处均是BACKUP state BACKUP interface ens33 virtual_router_id 55 # 优先级 priority 90 advert_int 1 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 192.168.137.13 } }
node2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 $ vim /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id vip3 } vrrp_instance VI_1 { # 三台配置此处均是BACKUP state BACKUP interface ens33 virtual_router_id 55 # 优先级 priority 85 advert_int 1 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 192.168.137.13 } }
重启服务,自启
1 2 $ systemctl restart keepalived $ systemctl enable keepalived
在优先级最高的那台查看VIP地址是否建立
验证可以使用新建一个终端来验证是否会连接到优先级高的那台服务器
证书 Kubernetes系统的各组件需要使⽤TLS证书对通信进⾏加密,本⽂档使⽤CloudFlare的PKI⼯具集cfssl来⽣成Certificate Authority (CA)和其它证书;⽣成的CA证书和秘钥⽂件如下:
ca-key.pem
ca.pem
kubernetes-key.pem
kubernetes.pem
kube-proxy.pem
kube-proxy-key.pem
admin.pem
admin-key.pem
使⽤证书的组件如下:
etcd:使⽤ ca.pem、kubernetes-key.pem、kubernetes.pem;
kube-apiserver:使⽤ ca.pem、kubernetes-key.pem、kubernetes.pem;
kubelet:使⽤ ca.pem;
kube-proxy:使⽤ ca.pem、kube-proxy-key.pem、kubeproxy.pem;
kubectl:使⽤ ca.pem、admin-key.pem、admin.pem;
kube-controller-manager:使⽤ ca-key.pem、ca.pem
注意:以下操作都在 api 节点即 192.168.137.10 这台主机上执⾏,证书只需要创建⼀次即可,以后在向集群中添加新节点时只要将**/etc/kubernetes/**⽬录下的证书拷⻉到新节点上即可。
安装cfssl 1 2 3 4 5 6 7 8 9 10 wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 chmod +x cfssl_linux-amd64 mv cfssl_linux-amd64 /usr/local/bin/cfssl wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 chmod +x cfssljson_linux-amd64 mv cfssljson_linux-amd64 /usr/local/bin/cfssljson wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 chmod +x cfssl-certinfo_linux-amd64 mv cfssl-certinfo_linux-amd64 /usr/local/bin/cfssl-certinfo export PATH=/usr/local/bin:$PATH
创建ca配置文件 1 2 3 4 5 6 7 mkdir /root/ssl cd /root/ssl # 下面的操作是将模板文件复制过来,可以不操作,直接建立。 # cfssl print-defaults config > config.json # cfssl print-defaults csr > csr.json # cat config.json > ca-config.json
根据config.json⽂件的格式创建如下的ca-config.json⽂件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 vim ca-config.json { "signing": { "default": { "expiry": "87600h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "87600h" } } } }
字段说明:
ca-config.json :可以定义多个profiles,分别指定不同的过期时间、使⽤场景等参数;后续在签名证书时使⽤某个profile;
signing :表示该证书可⽤于签名其它证书;⽣成的 ca.pem 证书中CA=TRUE ;
server auth :表示client可以⽤该 CA 对server提供的证书进⾏验证;
client auth :表示server可以⽤该CA对client提供的证书进⾏验证;
创建CA证书 创建 CA 证书签名请求 创建 ca-csr.json ⽂件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 vim ca-csr.json { "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "k8s", "OU": "System" } ] }
“CN”: Common Name ,kube-apiserver 从证书中提取该字段作为请求的⽤户名 (User Name);浏览器使⽤该字段验证⽹站是否合法;
“O”: Organization ,kube-apiserver 从证书中提取该字段作为请求⽤户所属的组(Group);
⽣成 CA 证书和私钥ca-key.pem ca.pem 1 2 3 $ cfssl gencert -initca ca-csr.json | cfssljson -bare ca $ ls ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem config.json csr.json
创建 kubernetes 证书 创建 kubernetes 证书签名请求⽂件 kubernetes-csr.json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 cat ca-csr.json > kubernetes-csr.json vim kubernetes-csr.json { "CN": "kubernetes", "hosts": [ "127.0.0.1", "192.168.137.10", "192.168.137.11", "192.168.137.12", "192.168.137.13", "10.254.0.1", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "k8s", "OU": "System" } ] }
如果 hosts 字段不为空则需要指定授权使⽤该证书的 IP 或域名列表,由于该证书后续被 etcd 集群和 kubernetes master集群使⽤,所以上⾯分别指定了 etcd 集群、 kubernetes master集群的主机 IP 和kubernetes 服务的集群 IP (⼀般是 kube-apiserver 指定的service-cluster-ip-range ⽹段的第⼀个IP,如 10.254.0.1。
hosts中的内容可以为空,即使按照上⾯的置,向集群中增加新节点后也不需要重新⽣成证书。
⽣成 kubernetes 证书和私钥kubernetes-key.pem kubernetes.pem 1 2 3 $ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kubernetes-csr.json | cfssljson -bare kubernetes $ ls kubernetes* kubernetes.csr kubernetes-csr.json kubernetes-key.pem kubernetes.pem
创建admin证书 创建 admin 证书签名请求⽂件 admin-csr.json : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 cat ca-csr.json > admin-csr.json vim admin-csr.json { "CN": "admin", "hosts":[], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "system:masters", "OU": "System" } ] }
后续 kube-apiserver 使⽤ RBAC 对客户端(如 kubelet 、 kubeproxy、 Pod)请求进⾏授权;
kube-apiserver 预定义了⼀些 RBAC 使⽤的 RoleBindings ,如cluster-admin 将Group system:masters 与 Role cluster-admin绑定,该 Role 授予了调⽤kube-apiserver 的所有 API 的权限;
OU 指定该证书的 Group 为 system:masters , kubelet 使⽤该证书访问kube-apiserver 时 ,由于证书被 CA签名,所以认证通过,同时由于证书⽤户组为经过预授权的 system:masters,所以被授予访问所有 API 的权限;
⽣成 admin 证书和私钥admin-key.pem admin.pem 1 2 3 $ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes admin-csr.json | cfssljson -bare admin $ ls admin* admin.csr admin-csr.json admin-key.pem admin.pem
创建 kube-controller-manager 证书 创建 kube-controller-manager 证书签名请求⽂件 kube-controller-manager-csr.json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 $ vim kube-controller-manager-csr.json { "CN": "system:kube-controller-manager", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "system:kube-controller-manager", "OU": "System" } ] }
⽣成kube-controller-manager证书和私钥kube-controller-manager-key.pem kube-controller-manager.pem 1 2 3 $ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-controller-manager-csr.json | cfssljson -bare kube-controller-manager $ ls kube-controller-manager* kube-controller-manager.csr kube-controller-manager-csr.json kube-controller-manager-key.pem kube-controller-manager.pem
创建 kube-scheduler 证书 创建kube-scheduler 证书签名请求⽂件 kube-scheduler-csr.json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $ vim kube-scheduler-csr.json { "CN":"system:kube-scheduler", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "system:kube-scheduler", "OU": "System" } ] }
⽣成kube-scheduler证书和私钥kube-scheduler-key.pem kube-scheduler.pem 1 2 3 $ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-scheduler-csr.json | cfssljson -bare kube-scheduler $ ls kube-scheduler* kube-scheduler.csr kube-scheduler-csr.json kube-scheduler-key.pem kube-scheduler.pem
创建 front-proxy 证书 创建 front-proxy 证书签名请求⽂件front-proxy-ca-csr.json 1 2 3 4 5 6 7 8 9 10 vim front-proxy-ca-csr.json { "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 } }
生成 front-proxy-ca证书和私钥front-proxy-ca-key.pem front-proxy-ca.pem 1 2 3 $ cfssl gencert -initca front-proxy-ca-csr.json | cfssljson -bare front-proxy-ca $ ls front-proxy-ca* front-proxy-ca.csr front-proxy-ca-csr.json front-proxy-ca-key.pem front-proxy-ca.pem
创建 front-proxy-client 证书签名请求⽂件 front-proxy-client-csr.json 1 2 3 4 5 6 7 8 9 10 vim front-proxy-client-csr.json { "CN": "front-proxy-client", "key": { "algo": "rsa", "size": 2048 } }
⽣成front-proxy-client证书和私钥front-proxy-client-key.pem front-proxy-client.pem 1 2 3 4 5 6 7 8 $ cfssl gencert \ -ca=front-proxy-ca.pem \ -ca-key=front-proxy-ca-key.pem \ -config=ca-config.json \ -profile=kubernetes \ front-proxy-client-csr.json | cfssljson -bare front-proxy-client $ ls front-proxy-client* front-proxy-client.csr front-proxy-client-csr.json front-proxy-client-key.pem front-proxy-client.pem
校验证书 以 kubernetes 证书为例
使⽤ opsnssl 命令 1 openssl x509 -noout -text -in kubernetes.pem
确认 Issuer 字段的内容和 ca-csr.json ⼀致;
确认 Subject 字段的内容和 kubernetes-csr.json ⼀致;
确认 X509v3 Subject Alternative Name 字段的内容和 kubernetescsr.json ⼀致;
确认 X509v3 Key Usage、Extended Key Usage 字段的内容和 caconfig.json 中kubernetes profile ⼀致;
使⽤ cfssl-certinfo 命令 1 cfssl-certinfo -cert kubernetes.pem
分发证书 三台服务器都要执行
将⽣成的证书和秘钥⽂件(后缀名为 .pem )拷⻉到所有机器的/etc/kubernetes/ssl
1 2 mkdir -p /etc/kubernetes/ssl cp -rf *.pem /etc/kubernetes/ssl
Haproxy 1.结合keepalived保证整个集群的HA(高可用)
2.使用 keepalived 和 haproxy 实现 kube-apiserver 高可用的步骤:
keepalived 提供 kube-apiserver 对外服务的 VIP;
haproxy 监听 VIP,后端连接所有 kube-apiserver实例,提供健康检查和负载均衡功能;
运行 keepalived 和 haproxy 的节点称为 LB 节点。由于 keepalived是一主多备运行模式,故至少两个 LB 节点。复用 master 节点的三台机器,haproxy监听的端口(9443) 需要与 kube-apiserver 的端口6443不同,避免冲突。
keepalived 在运行过程中周期检查本机的 haproxy 进程状态,如果检测到 haproxy进程异常,则触发重新选主的过程,VIP 将飘移到新选出来的主节点,从而实现 VIP的高可用。
所有组件(如kubectl、kube-apiserver、kube-controller-manager、kube-scheduler、kubelet等)都通过VIP和haproxy监听的9443 端口访问kube-apiserver服务。
三台服务器都要执行
安装haproxy 1 $ yum -y install haproxy
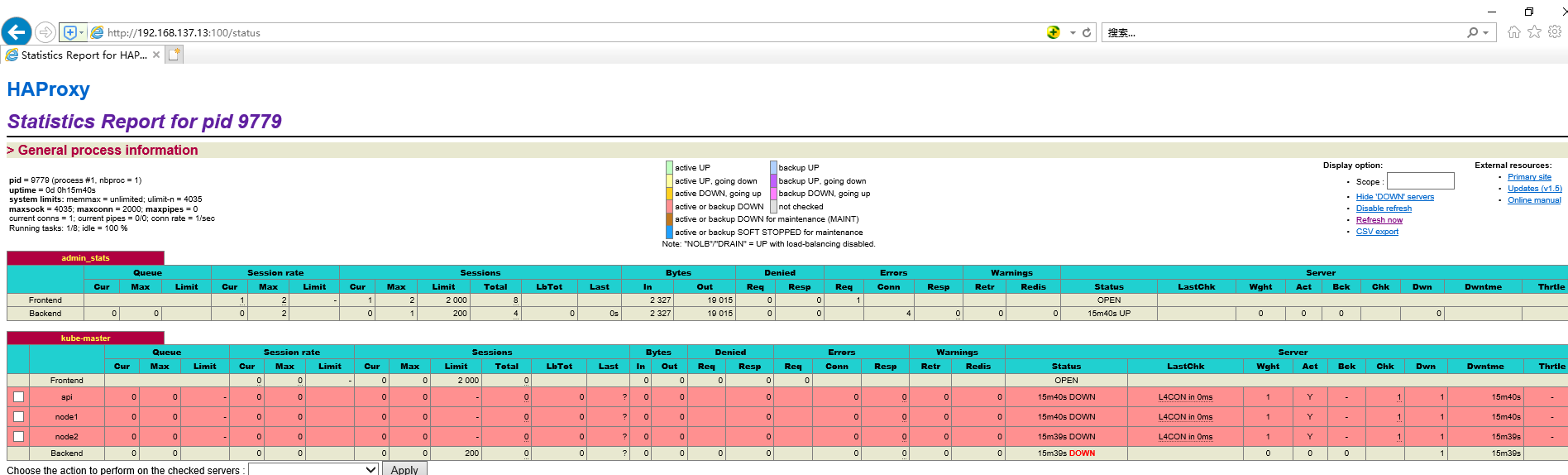
修改haproxy配置文件如下,这里将9443端口(这个端口将代理到各k8s集群api端口6443)和haproxy进程绑定在一起,并定义后端服务器。并且开启100端口监听haproxy进程状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 # haproxy 配置文件: cat> haproxy.cfg<<EOF global log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy stats socket /run/haproxy/admin.sock mode 660 level admin stats timeout 30s user haproxy group haproxy daemon nbproc 1 defaults log global timeout connect 5000 timeout client 10m timeout server 10m listen admin_stats bind 0.0.0.0:100 mode http log 127.0.0.1 local0 err stats refresh 30s stats uri /status stats realm welcome login\ Haproxy stats auth admin:123456 stats hide-version stats admin if TRUE listen kube-master bind 0.0.0.0:9443 mode tcp option tcplog balance source server api 192.168.137.10:6443 check inter 2000 fall 2 rise 2 weight 1 server node1 192.168.137.11:6443 check inter 2000 fall 2 rise 2 weight 1 server node2 192.168.137.12:6443 check inter 2000 fall 2 rise 2 weight 1 EOF
建立haproxy的工作目录并启动服务,开机自启,工作目录/run/haproxy重启服务器会丢失,所以将其加入到随系统启动而建立
1 2 3 4 5 6 # 赋予执行权限 chmod +x /etc/rc.d/rc.local echo "mkdir -p /run/haproxy" >> /etc/rc.local mkdir -p /run/haproxy systemctl start haproxy systemctl enable haproxy
查看是否监听9443端口。
1 2 netstat -lntp | grep 9443 tcp 0 0 0.0.0.0:9443 0.0.0.0:* LISTEN 10019/haproxy
增加keepalived配置,使其嗅探haproxy的状态 三台服务器都要执行
1 2 3 4 5 6 7 8 9 10 11 12 vrrp_script check-haproxy { script "killall -0 haproxy" interval 1 weight -20 } 并且在VIP下面配置track_script以对应上面的脚本 virtual_ipaddress { 192.168.137.13 } track_script { check-haproxy }
使用 killall -0 haproxy 命令检查所在节点的 haproxy
例如api节点配置
重启服务
1 systemctl restart keepalived
验证HA效果,用户名和密码是之前开启的100端口中定义的admin:123456
kubectl kubectl作为k8s集群的客户端工具,首先需要安装来生成集群配置文件kubeconfighttps://dl.k8s.io/v1.12.4/kubernetes-server-linux-amd64.tar.gz
因为我们要做HA集群,所以这里三台服务器都会作为api服务器,所以我们直接将所有二进制程序放到指定地方
1 2 3 4 wget https://dl.k8s.io/v1.12.4/kubernetes-server-linux-amd64.tar.gz tar zxf kubernetes-server-linux-amd64.tar.gz cd kubernetes cp -rf server/bin/{kube-apiserver,kube-controller-manager,kube-scheduler,kubectl,kube-proxy,kubelet} /usr/local/bin/
创建 kubectl所需kubeconfig文件 主要是用于kubectl命令和kubelet服务进行获取apiserver信息并且集群角色cluster-admin与自建用户admin进行绑定
kubeconfig.sh
1 2 3 4 5 export KUBE_APISERVER="https://192.168.137.13:9443" kubectl config set-cluster kubernetes --certificate-authority=/etc/kubernetes/ssl/ca.pem --embed-certs=true --server=${KUBE_APISERVER} kubectl config set-credentials admin --client-certificate=/etc/kubernetes/ssl/admin.pem --embed-certs=true --client-key=/etc/kubernetes/ssl/admin-key.pem kubectl config set-context kubernetes --cluster=kubernetes --user=admin kubectl config use-context kubernetes
KUBEAPISERVER变量中定义的是VIP地址。
admin.pem证书OU字段值为 system:masters,kube-apiserver预定义的RoleBinding cluster-admin将Group system:masters与 Role cluster-admin绑定,该 Role 授予了调⽤ kube-apiserver相关 API 的权限;
⽣成的 kubeconfig 被保存到 ~/.kube/config ⽂件;
k8s集群建立前预备配置文件 创建 TLS Bootstrapping token文件 Token auth file Token可以是任意的包涵128 bit的字符串,可以使⽤安全的随机数发⽣器⽣成
1 export BOOTSTRAP_TOKEN=$(head -c 16 /dev/urandom | od -An -t x |tr -d ' ')
建立token.csv
1 2 3 cat > token.csv << EOF $ {BOOTSTRAP_TOKEN},kubelet-bootstrap,10001,"system:kubelet-bootstrap" EOF
1 2 cat token.csv b156d4d29fe7a73e554a145fc996e3c6,kubelet-bootstrap,10001,"system:kubelet-bootstrap"
注意:在进⾏后续操作前请检查 token.csv ⽂件,确认其中的**${BOOTSTRAP_TOKEN}** 环境变量已经被真实的值替换。
BOOTSTRAP_TOKEN 将被写⼊到 kube-apiserver 使⽤的 token.csv ⽂件和 kubelet使⽤的 bootstrap.kubeconfig ⽂件,如果后续重新⽣成了BOOTSTRAP_TOKEN,则需要:
更新 token.csv ⽂件,分发到所有机器 (master 和 node)的/etc/kubernetes/⽬录下,分发到node节点上⾮必需;
重新⽣成 bootstrap.kubeconfig ⽂件,分发到所有 node 机器的/etc/kubernetes/⽬录下;
重启 kube-apiserver 和 kubelet 进程;
重新 approve kubelet 的 csr 请求;
!!!注意,需要将token.csv文件复制到另外两台服务器,不要重新生成token.csv文件,文件目录是之前的ssl文件的上一级目录/etc/kubernetes
1 cp token.csv /etc/kubernetes/
创建服务需要的kubeconfig文件 在开启了 TLS 的集群中,每当与集群交互的时候少不了的是身份认证,使用kubeconfig(即证书) 和 token 两种认证方式是最简单也最通用的认证方式。
总之kubeconfig就是为访问集群所作的配置。
创建 kubelet服务所需 bootstrapping.kubeconfig文件 主要是用于生成的bootstrap.kubeconfig提供给kubelet进行node注册
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 cd /etc/kubernetes export KUBE_APISERVER="https://192.168.137.13:9443" # 设置集群参数 kubectl config set-cluster kubernetes \ --certificate-authority=/etc/kubernetes/ssl/ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=bootstrap.kubeconfig # 设置客户端认证参数 kubectl config set-credentials kubelet-bootstrap \ --token=${BOOTSTRAP_TOKEN} \ --kubeconfig=bootstrap.kubeconfig # 设置上下文参数 kubectl config set-context default \ --cluster=kubernetes \ --user=kubelet-bootstrap \ --kubeconfig=bootstrap.kubeconfig # 设置默认上下文 kubectl config use-context default --kubeconfig=bootstrap.kubeconfig
上述也用到了变量BOOTSTRAP_TOKEN,所以kubeconfig生成后也是复制到其他服务
–embed-certs 为 true 时表示将 certificate-authority 证书写⼊到⽣成的bootstrap.kubeconfig⽂件中;
设置客户端认证参数时没有指定秘钥和证书,后续由 kubeapiserver⾃动⽣成;
创建 kubelet服务所需 kubelet.kubeconfig文件 这里我们直接使用/root/.kube/config文件,也可以自己建立kubelet证书后来生成
创建 kube-controller-manager服务所需kube-controller-manager.kubeconfig ⽂件 kube-controller-manager.kubeconfig.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 cd /etc/kubernetes export KUBE_APISERVER="https://192.168.137.13:9443" # 设置集群参数 kubectl config set-cluster kubernetes \ --certificate-authority=/etc/kubernetes/ssl/ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=kube-controller-manager.kubeconfig # 设置客户端认证参数 kubectl config set-credentials system:kube-controller-manager \ --client-certificate=/etc/kubernetes/ssl/kube-controller-manager.pem \ --client-key=/etc/kubernetes/ssl/kube-controller-manager-key.pem \ --embed-certs=true \ --kubeconfig=kube-controller-manager.kubeconfig # 设置上下文参数 kubectl config set-context system:kube-controller-manager@kubernetes \ --cluster=kubernetes \ --user=system:kube-controller-manager \ --kubeconfig=kube-controller-manager.kubeconfig # 设置默认上下文 kubectl config use-context system:kube-controller-manager@kubernetes --kubeconfig=kube-controller-manager.kubeconfig
创建 kube-scheduler服务所需kube-scheduler.kubeconfig ⽂件 kube-scheduler.kubeconfig.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 cd /etc/kubernetes export KUBE_APISERVER="https://192.168.137.13:9443" # 设置集群参数 kubectl config set-cluster kubernetes \ --certificate-authority=/etc/kubernetes/ssl/ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=kube-scheduler.kubeconfig # 设置客户端认证参数 kubectl config set-credentials system:kube-scheduler \ --client-certificate=/etc/kubernetes/ssl/kube-scheduler.pem \ --client-key=/etc/kubernetes/ssl/kube-scheduler-key.pem \ --embed-certs=true \ --kubeconfig=kube-scheduler.kubeconfig # 设置上下文参数 kubectl config set-context system:kube-scheduler@kubernetes \ --cluster=kubernetes \ --user=system:kube-scheduler \ --kubeconfig=kube-scheduler.kubeconfig # 设置默认上下文 kubectl config use-context system:kube-scheduler@kubernetes --kubeconfig=kube-scheduler.kubeconfig
执行脚本文件生成kubeconfig文件 1 2 3 source /root/bootstrap.kubeconfig.sh source /root/kube-controller-manager.kubeconfig.sh source /root/kube-scheduler.kubeconfig.sh
分发 kubeconfig ⽂件 将 kubeconfig ⽂件分发到其他服务器的 /etc/kubernetes/ ⽬录,具体怎么分发自己操作
Etcd3.3.4 三台服务器都要执行
TLS 认证⽂件 需要为 etcd 集群创建加密通信的 TLS 证书,这⾥复⽤以前创建的kubernetes 证书
ca.pem kubernetes-key.pem kubernetes.pem
kubernetes 证书的 hosts 字段列表中包含上⾯三台服务器的IP,否则后续证书校验会失败;
1 2 3 $ wget https://github.com/coreos/etcd/releases/download/v3.3.4/etcd-v3.3.4-linux-amd64.tar.gz $ tar zxf etcd-v3.3.4-linux-amd64.tar.gz $ mv etcd-v3.3.4-linux-amd64/etcd* /usr/local /bin/
ectd服务services配置文件 /usr/lib/systemd/system/etcd.service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 [Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target Documentation=https://github.com/coreos [Service] Type=notify WorkingDirectory=/var/lib/etcd/ EnvironmentFile=-/etc/etcd/etcd.conf ExecStart=/usr/local/bin/etcd --name ${ETCD_NAME} --cert-file=/etc/kubernetes/ssl/kubernetes.pem --key-file=/etc/kubernetes/ssl/kubernetes-key.pem --peer-cert-file=/etc/kubernetes/ssl/kubernetes.pem --peer-key-file=/etc/kubernetes/ssl/kubernetes-key.pem --trusted-ca-file=/etc/kubernetes/ssl/ca.pem --peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem --initial-advertise-peer-urls ${ETCD_INITIAL_ADVERTISE_PEER_URLS} --listen-peer-urls ${ETCD_LISTEN_PEER_URLS} --listen-client-urls ${ETCD_LISTEN_CLIENT_URLS},http://127.0.0.1:2379 --advertise-client-urls ${ETCD_ADVERTISE_CLIENT_URLS} --initial-cluster-token ${ETCD_INITIAL_CLUSTER_TOKEN} --initial-cluster-infra1=https://192.168.137.10:2380,infra2=https://192.168.137.11:2380,infra3=https://192.168.137.12:2380 --initial-cluster-state new --data-dir=${ETCD_DATA_DIR} Restart=on-failure RestartSec=5 LimitNOFILE=65536 [Install] WantedBy=multi-user.target
指定 etcd 的⼯作⽬录为 /var/lib/etcd ,数据⽬录为/var/lib/etcd,需在启动服务前创建这两个⽬录;
为了保证通信安全,需要指定 etcd 的公私钥(cert-file和key-file)、Peers通信的公私钥和 CA证书(peer-cert-file、peer-key-file、peertrusted-ca-file)、客户端的CA证书(trusted-ca-file);
创建 kubernetes.pem 证书时使⽤的 kubernetes-csr.json ⽂件的hosts字段包含所有 etcd 节点的IP ,否则证书校验会出错;
–initial-cluster-state 值为 new 时, –name 的参数值必须位于–initial-cluster 列表中;1 2 mkdir /var/lib/etcd mkdir /etc/etcd
环境变量配置⽂件 /etc/etcd/etcd.conf
1 2 3 4 5 6 7 8 9 10 # [member] ETCD_NAME=infra1 ETCD_DATA_DIR="/var/lib/etcd" ETCD_LISTEN_PEER_URLS="https://192.168.137.10:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.137.10:2379" # [cluster] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.137.10:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_ADVERTISE_CLIENT_URLS=https://192.168.137.10:2379
这是192.168.137.10节点的配置,其他两个etcd节点只要将上⾯的IP地址改成相应节点的IP地址即可。ETCD_NAME换成对应节点的infra1/2/3。
1 2 3 4 5 6 7 8 9 # [member] ETCD_NAME=infra2 ETCD_DATA_DIR="/var/lib/etcd" ETCD_LISTEN_PEER_URLS="https://192.168.137.11:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.137.11:2379" # [cluster] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.137.11:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_ADVERTISE_CLIENT_URLS=https://192.168.137.11:2379
1 2 3 4 5 6 7 8 9 # [member] ETCD_NAME=infra3 ETCD_DATA_DIR="/var/lib/etcd" ETCD_LISTEN_PEER_URLS="https://192.168.137.12:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.137.12:2379" # [cluster] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.137.12:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.137.12:2379"
启动etcd服务 1 2 3 systemctl daemon-reload systemctl enable etcd systemctl start etcd
验证
1 2 3 4 5 etcdctl \ --ca-file=/etc/kubernetes/ssl/ca.pem \ --cert-file=/etc/kubernetes/ssl/kubernetes.pem \ --key-file=/etc/kubernetes/ssl/kubernetes-key.pem \ cluster-health
结果最后⼀⾏为 cluster is healthy 时表示集群服务正常。
kube-apiserver 创建 kube-apiserver的服务配置⽂件 /usr/lib/systemd/system/kube-apiserver.service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [Unit] Description=Kubernetes API Service Documentation=https://github.com/GoogleCloudPlatform/kubernetes After=network.target After=etcd.service [Service] EnvironmentFile=-/etc/kubernetes/apiserver ExecStart=/usr/local/bin/kube-apiserver \ $ KUBE_API_ARGS Restart=on-failure Type=notify LimitNOFILE=65536 [Install] WantedBy=multi-user.target
apiserver服务配置⽂件 /etc/kubernetes/apiserver 内容 此处是主机名api的服务器配置,另外两台服务器修改其中的IP地址即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 KUBE_API_ARGS="--advertise-address=192.168.137.10 \ --allow-privileged=true \ --client-ca-file=/etc/kubernetes/ssl/ca.pem \ --disable-admission-plugins=PersistentVolumeLabel \ --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \ --authorization-mode=RBAC,Node \ --token-auth-file=/etc/kubernetes/token.csv \ --enable-bootstrap-token-auth=true \ --etcd-cafile=/etc/kubernetes/ssl/ca.pem \ --etcd-certfile=/etc/kubernetes/ssl/kubernetes.pem \ --etcd-keyfile=/etc/kubernetes/ssl/kubernetes-key.pem \ --etcd-servers=https://192.168.137.10:2379,https://192.168.137.11:2379,https://192.168.137.12:2379 \ --insecure-port=0 \ --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname \ --secure-port=6443 \ --service-account-key-file=/etc/kubernetes/ssl/ca-key.pem \ --service-cluster-ip-range=10.254.0.0/16 \ --tls-cert-file=/etc/kubernetes/ssl/kubernetes.pem \ --tls-private-key-file=/etc/kubernetes/ssl/kubernetes-key.pem \ --kubelet-client-certificate=/etc/kubernetes/ssl/admin.pem \ --kubelet-client-key=/etc/kubernetes/ssl/admin-key.pem\ --proxy-client-cert-file=/etc/kubernetes/ssl/front-proxy-client.pem \ --proxy-client-key-file=/etc/kubernetes/ssl/front-proxy-client-key.pem \ --requestheader-allowed-names=front-proxy-client \ --requestheader-client-ca-file=/etc/kubernetes/ssl/front-proxy-ca.pem \ --requestheader-extra-headers-prefix=X-Remote-Extra- \ --requestheader-group-headers=X-Remote-Group \ --requestheader-username-headers=X-Remote-User \ --v=2 \ --logtostderr=true \ --audit-log-maxage=30 \ --audit-log-maxbackup=3 \ --audit-log-maxsize=100 \ --audit-log-path=/var/log/kubernetes/audit.log \ --audit-policy-file=/etc/kubernetes/audit-policy.yml \ --experimental-encryption-provider-config=/etc/kubernetes/encryption.yaml \ --event-ttl=1h"
–authorization-mode=Node,RBAC: 开启 Node 和 RBAC授权模式,拒绝未授权的请求;
–enable-admission-plugins:启用 ServiceAccount 和 NodeRestriction;
–service-account-key-file:签名 ServiceAccount Token的公钥文件,kube-controller-manager 的 –service-account-private-key-file指定私钥文件,两者配对使用;
–tls-*-file:指定 apiserver 使用的证书、私钥和 CA 文件。–client-ca-file用于验证 client (kue-controller-manager、kube-scheduler、kubelet、kube-proxy等)请求所带的证书;
–kubelet-client-certificate、–kubelet-client-key:如果指定,则使用 https访问 kubelet APIs;需要为 kubernete 用户定义 RBAC 规则,否则无权访问 kubeletAPI;
–service-cluster-ip-range: 指定 Service Cluster IP 地址段;
–service-node-port-range: 指定 NodePort 的端口范围;
–runtime-config=api/all=true: 启用所有版本的 APIs,如autoscaling/v2alpha1;
–enable-bootstrap-token-auth:启用 kubelet bootstrap 的 token 认证;
–kubelet-client-certificate=/etc/kubernetes/ssl/admin.pem这里我为什么不重新生成kubelet的证书呢,因为后面安装kubelet的时候使用的kubeconfig就是将admin用户生成给kubectl使用的kubeconfig(即.kube/config文件)复制给他使用了,所以这里直接使用admin证书,当然你也可以去生成kubelet证书。
–kubelet-client-key=/etc/kubernetes/ssl/admin-key.pem,同上述
–proxy-client-cert-file=/etc/kubernetes/ssl/front-proxy-client.pem
–requestheader-allowed-names=front-proxy-client
–audit-policy-file=/etc/kubernetes/audit-policy.yml ,文件内容如下https://github.com/huisebug/k8s1.12-Ecosphere/blob/master/etc/kubernetes/audit-policy.yml
–experimental-encryption-provider-config:启用加密特性;文件生成如下https://github.com/huisebug/k8s1.12-Ecosphere/blob/master/etc/kubernetes/encryption.yaml https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/etc/kubernetes/encryption-source.yaml 1 2 3 4 5 # 下载后将其更名为encryption.yaml $ mv encryption-source.yaml encryption.yaml $ ENCRYPT_SECRET=$( head -c 32 /dev/urandom | base64 ) $ sed -ri "/secret:/s#(: ).+#\1${ENCRYPT_SECRET} #" encryption.yaml
node1的apiserver服务配置文件只需要修改此处–advertise-address=192.168.137.11即可;
node2的apiserver服务配置文件只需要修改此处–advertise-address=192.168.137.12即可;
启动kube-apiserver 1 2 3 4 systemctl daemon-reload systemctl enable kube-apiserver systemctl start kube-apiserver systemctl status kube-apiserver
kube-controller-manager 三台服务器都要执行
创建 kube-controller-manager服务配置⽂件 /usr/lib/systemd/system/kube-controller-manager.service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [Unit] Description=Kubernetes Controller Manager Documentation=https://github.com/GoogleCloudPlatform/kubernetes [Service] EnvironmentFile=-/etc/kubernetes/controller-manager ExecStart=/usr/local/bin/kube-controller-manager $ KUBE_CONTROLLER_MANAGER_ARGS Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target
controller-manager服务配置⽂件 /etc/kubernetes/controller-manager /etc/kubernetes/controller-manager
1 2 3 4 5 6 7 8 9 10 11 12 KUBE_CONTROLLER_MANAGER_ARGS="--address=0.0.0.0 \ --allocate-node-cidrs=true \ --cluster-cidr=10.10.0.0/16 \ --cluster-signing-cert-file=/etc/kubernetes/ssl/ca.pem \ --cluster-signing-key-file=/etc/kubernetes/ssl/ca-key.pem \ --controllers=*,bootstrapsigner,tokencleaner \ --kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig \ --leader-elect=true \ --node-cidr-mask-size=24 \ --root-ca-file=/etc/kubernetes/ssl/ca.pem \ --service-account-private-key-file=/etc/kubernetes/ssl/ca-key.pem \ --use-service-account-credentials=true "
–address=0.0.0.0此处为了方便后续的prometheus-operator访问服务端口设置为所有网卡可以访问,之前设置的是127.0.0.1
–allocate-node-cidrs=true,您的Kubernetes控制器管理器配置为分配pod CIDR(即通过传递–allocate-node-cidrs=true给控制器管理器)
–cluster-cidr=10.10.0.0/16,您的Kubernetes控制器管理器已经提供了一个cluster-cidr(即通过传递–cluster-cidr=10.10.0.0/16,默认情况下清单需要)。
启动 kube-controller-manager 1 2 3 4 systemctl daemon-reload systemctl enable kube-controller-manager systemctl start kube-controller-manager systemctl status kube-controller-manager
kube-scheduler 三台服务器都要执行
创建 kube-scheduler服务配置⽂件 /usr/lib/systemd/system/kube-scheduler.service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [Unit] Description=Kubernetes Scheduler Plugin Documentation=https://github.com/GoogleCloudPlatform/kubernetes [Service] EnvironmentFile=-/etc/kubernetes/scheduler ExecStart=/usr/local/bin/kube-scheduler $ KUBE_SCHEDULER_ARGS Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target [Install] WantedBy=multi-user.target
scheduler服务配置⽂件 /etc/kubernetes/scheduler /etc/kubernetes/scheduler
1 2 3 4 KUBE_SCHEDULER_ARGS="--address=0.0.0.0 \ --leader-elect=true \ --kubeconfig=/etc/kubernetes/kube-scheduler.kubeconfig"
–address=0.0.0.0此处为了方便后续的prometheus-operator访问服务端口设置为所有网卡可以访问,之前设置的是127.0.0.1
启动 kube-scheduler 1 2 3 4 systemctl daemon-reload systemctl enable kube-scheduler systemctl start kube-scheduler systemctl status kube-scheduler
至此Master三大组件安装完成 查看运行状态
1 2 for i in kube-apiserver kube-controller-manager kube-scheduler; do systemctl restart $i ; done for i in kube-apiserver kube-controller-manager kube-scheduler; do systemctl status $i -l ; done
验证集群
1 2 3 4 5 6 7 8 9 10 $ kubectl cluster-info Kubernetes master is running at https://192.168.137.13:9443 $ kubectl get cs NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health":"true"} etcd-1 Healthy {"health":"true"} etcd-2 Healthy {"health":"true"}
Docker Docker从1.13版本开始调整了默认的防火墙规则,禁用了iptables filter表中FOWARD链,这样会引起Kubernetes集群中跨Node的Pod无法通信,因此docker安装完成后,还需要手动修改iptables规则。
三台服务器都要执行
安装docker 1 2 3 4 yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo yum makecache fast yum install -y docker-ce
编辑systemctl的Docker启动文件 1 sed -i "13i ExecStartPost=/usr/sbin/iptables -P FORWARD ACCEPT" /usr/lib/systemd/system/docker.service
修改docker参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 mkdir -p /etc/docker/ cat> /etc/docker/daemon.json<<EOF { "exec-opts": ["native.cgroupdriver=systemd"], "registry-mirrors": ["https://fz5yth0r.mirror.aliyuncs.com"], "storage-driver": "overlay2", "storage-opts": [ "overlay2.override_kernel_check=true" ], "log-driver": "json-file", "log-opts": { "max-size": "100m", "max-file": "3" } } EOF
启动docker 1 2 3 systemctl daemon-reload systemctl enable docker systemctl start docker
建立不加密的docker私有仓库方式 建立最简单的私库 1 2 3 4 docker run -d --restart=always --name dockerregistry \ -p 5000:5000 \ -v /huisebug/dockerimagestorehouse/registry:/var/lib/registry \ -v /huisebug/dockerimagestorehouse/config.yml:/etc/docker/registry/config.yml registry
config.yml内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 version: 0.1 log: fields: service: registry storage: delete: enabled: true cache: blobdescriptor: inmemory filesystem: rootdirectory: /var/lib/registry http: addr: :5000 headers: X-Content-Type-Options: [nosniff] health: storagedriver: enabled: true interval: 10s threshold: 3
更改docker的service文件增加–insecure-registry 192.168.137.10:5000
重启docker
1 2 systemctl daemon-reload systemctl restart docker
kubelet 三台服务器都要执行
创建 kubelet服务配置⽂件 /usr/lib/systemd/system/kubelet.service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [Unit] Description=Kubernetes Kubelet Server Documentation=https://github.com/GoogleCloudPlatform/kubernetes After=docker.service Requires=docker.service [Service] WorkingDirectory=/var/lib/kubelet EnvironmentFile=-/etc/kubernetes/kubelet ExecStart=/usr/local/bin/kubelet \ $ KUBELET_ARGS Restart=on-failure [Install] WantedBy=multi-user.target
创建工作目录,需要手动创建
kubelet服务配置文件/etc/kubernetes/kubelet /etc/kubernetes/kubelet
1 2 3 4 5 6 7 8 KUBELET_ARGS="--bootstrap-kubeconfig=/etc/kubernetes/bootstrap.kubeconfig \ --kubeconfig=/etc/kubernetes/kubelet.kubeconfig \ --config=/var/lib/kubelet/config.yaml \ --cni-bin-dir=/opt/cni/bin \ --cni-conf-dir=/etc/cni/net.d \ --network-plugin=cni"
bootstrap.kubeconfig之前我们已经建立了。kubelet 使⽤该⽂件中的⽤户名和 token向 kube-apiserver 发送 TLS Bootstrapping 请求;
–kubeconfig=/etc/kubernetes/kubelet.kubeconfig 中指定的 kubelet.kubeconfig⽂件在第⼀次启动kubelet之前并不存在,请看下⽂,当通过CSR请求后会⾃动⽣成kubelet.kubeconfig ⽂件,如果你的节点上已经⽣成了 ~/.kube/config⽂件,你可以将该⽂件拷⻉到该路径下,并重命名为 kubelet.kubeconfig,所有node节点可以共⽤同⼀个kubelet.kubeconfig⽂件,这样新添加的节点就不需要再创建CSR请求就能⾃动添加到kubernetes集群中。同样,在任意能够访问到kubernetes集群的主机上使⽤kubectl –kubeconfig 命令操作集群时,只要使⽤ ~/.kube/config⽂件就可以通过权限认证,因为这⾥⾯已经有认证信息并认为你是admin⽤户,对集群拥有所有权限。1 cp -rf /root/.kube/config /etc/kubernetes/kubelet.kubeconfig
并且分发到所有安装kubelet的服务器
建立文件目录
1 2 mkdir /etc/kubernetes/manifests echo " mkdir /etc/kubernetes/manifests" >> /etc/rc.local
!!!注意
hostPort不适用于CNI
使用hostPort 和CNI插件的组合将导致Kubernetes静默忽略hostPort 属性。
启动kubelet 1 2 3 4 systemctl daemon-reload systemctl enable kubelet systemctl start kubelet systemctl status kubelet
检查node状态 1 2 3 4 5 $ kubectl get node NAME STATUS ROLES AGE VERSION api.huisebug.com NotReady <none> 6m8s v1.12.4 node1.huisebug.com NotReady <none> 4s v1.12.4 node2.huisebug.com NotReady <none> 1s v1.12.4
可以看到状态为NotReady 因为缺少cni配置文件而导致kubelet服务(systemctl status kubelet -l)在日志中提示找不到配置而无法变为Ready
我们可以将/etc/cni/net.d/下的配置文件暂时建立10-calico.conflist,使状态变为Ready。后续再做修改或者删除。
1 2 $ mkdir -p /etc/cni/net.d/ $ vim /etc/cni/net.d/10-calico.conflist
参考下载地址:https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/etc/cni/net.d/10-calico.conflist
再次查看状态
1 2 3 4 5 $ kubectl get node NAME STATUS ROLES AGE VERSION api.huisebug.com Ready <none> 34m v1.12.4 node1.huisebug.com Ready <none> 28m v1.12.4 node2.huisebug.com Ready <none> 28m v1.12.4
kube-proxy 这里我们采用daemonsets方式建立
这里的代理模式使用的是ipvs,不再使用iptables,并且ipvs依赖于nf_conntrack_ipv4,所以需要将服务器的内核目录挂载到pod中
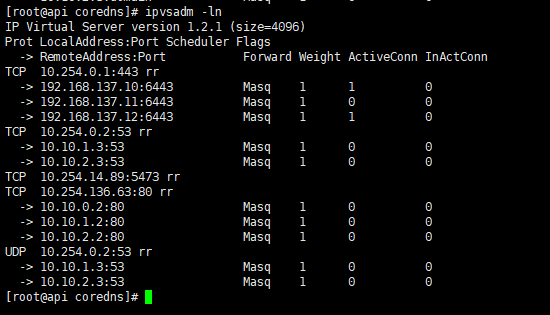
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 # 建立serviceaccount $ kubectl -n kube-system create serviceaccount kube-proxy # 建立集群角色绑定 kubectl create clusterrolebinding system:kube-proxy \ --clusterrole system:node-proxier \ --serviceaccount kube-system:kube-proxy # 建立daemonsets方式建立的pod和需要的参数configmap,参考地址: kubectl apply -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/kube-proxy/kube-proxy.yaml # 建立集群的第一个pod,会需要基础pod镜像,每台服务器执行一遍。拉取基础镜像。 docker pull huisebug/sec_re:pause3.1 && docker tag huisebug/sec_re:pause3.1 k8s.gcr.io/pause:3.1 # 查看状态 $ kubectl get pod --all-namespaces -o wide  # 通过ipvsadm查看 proxy 规则 $ ipvsadm -ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 10.254.0.1:443 rr -> 192.168.137.10:6443 Masq 1 0 0 -> 192.168.137.11:6443 Masq 1 0 0 -> 192.168.137.12:6443 Masq 1 0 0 # 确认使用ipvs模式 $ curl localhost:10249/proxyMode ipvs
至此Node三大组件安装完成 1 2 3 4 5 查看状态 for i in etcd kube-apiserver kube-controller-manager kube-scheduler kubelet docker; do systemctl status $i -l; done 重启所有二进制安装的 for i in etcd kube-apiserver kube-controller-manager kube-scheduler kubelet docker; do systemctl restart $i; done
Calico 环境要求,原打算是使用3.4.0版本,奈何失败了。
您的Kubernetes控制器管理器配置为分配pod CIDR(即通过传递–allocate-node-cidrs=true给控制器管理器)
您的Kubernetes控制器管理器已经提供了一个cluster-cidr(即通过传递–cluster-cidr=10.10.0.0/16,默认情况下清单需要)。
你有一个Kubernetes集群配置为使用CNI网络插件(即通过传递–network-plugin=cni给kubelet)
我犯了一个错误就是将cluster-cidr和cluster-range-ip配置成相同了,修改后如果出现pod无法建立,
1 2 rm -rf /var/lib/etcd/* for i in etcd kube-apiserver kube-controller-manager kube-scheduler kubelet docker; do systemctl restart $i ; done
1 2 export interface=ens33 kubectl apply -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/Calico/calico3.1.3node-ctl.yaml
记得上面要将cid地址修改为你的cidr地址
记得查看interface名称,系统不同网卡名称也不同
执行后检测pod建立情况
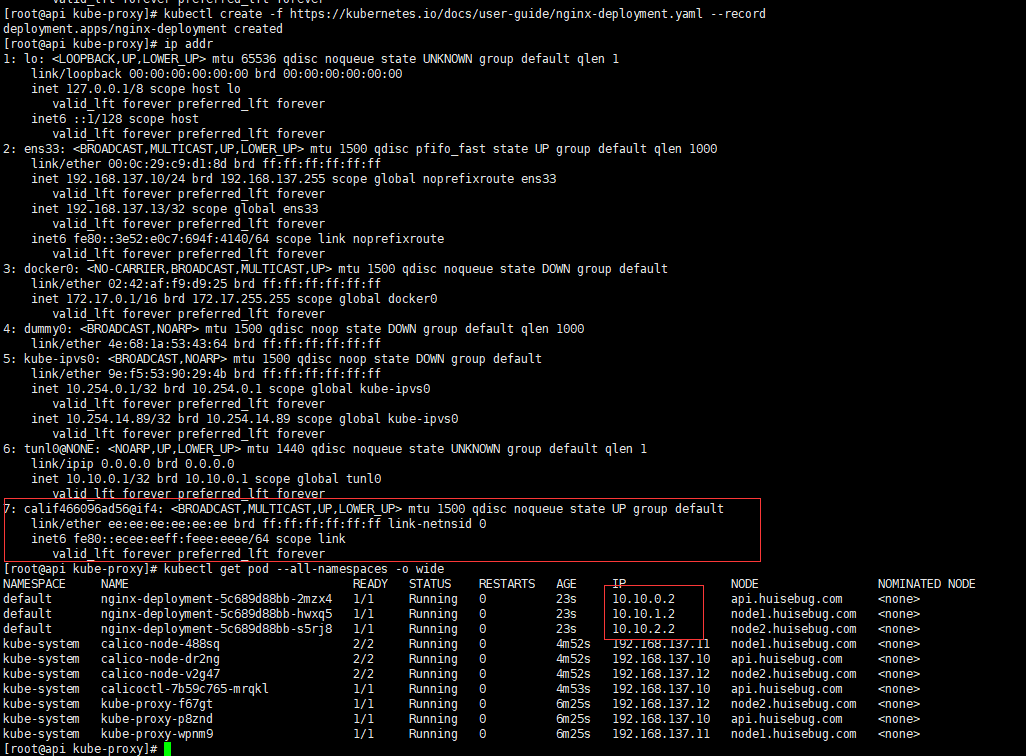
1 kubectl create -f https://kubernetes.io/docs/user-guide/nginx-deployment.yaml --record
再次查看网卡信息
验证不同节点的容器之间能否ping通
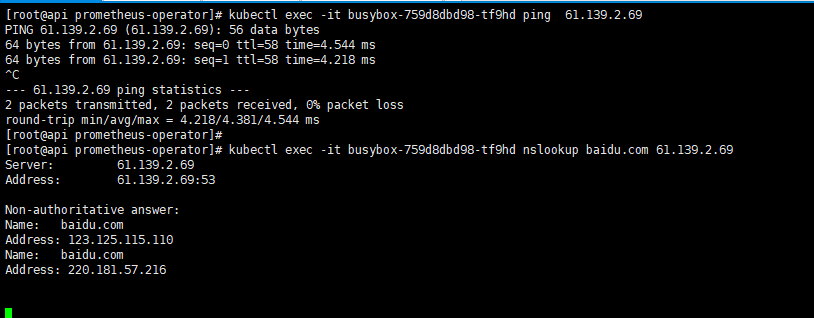
验证能否访问外网 建立一个测试工具pod,busybox需要一个持续输出,这里我将网关地址赋予它
1 2 3 kubectl run busybox --image=busybox --command -- ping 192.168.137.1 kubectl exec -it busybox-759d8dbd98-tf9hd ping 61.139.2.69 kubectl exec -it busybox-759d8dbd98-tf9hd nslookup baidu.com 61.139.2.69
至此calico安装完成。
问题汇总 如果kubectl get node一直是notready,
执行下面步骤
1 2 3 4 5 kubectl delete -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/Calico/calico3.1.3node-ctl.yaml # 三台服务器都执行 rm -rf /etc/cni/net.d/* kubectl apply -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/Calico/calico3.1.3node-ctl.yaml
Coredns 参考地址,记得将其中的集群ip地址修改为你在kubelet中定义的地址
1 kubectl apply -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/Coredns/coredns.yaml
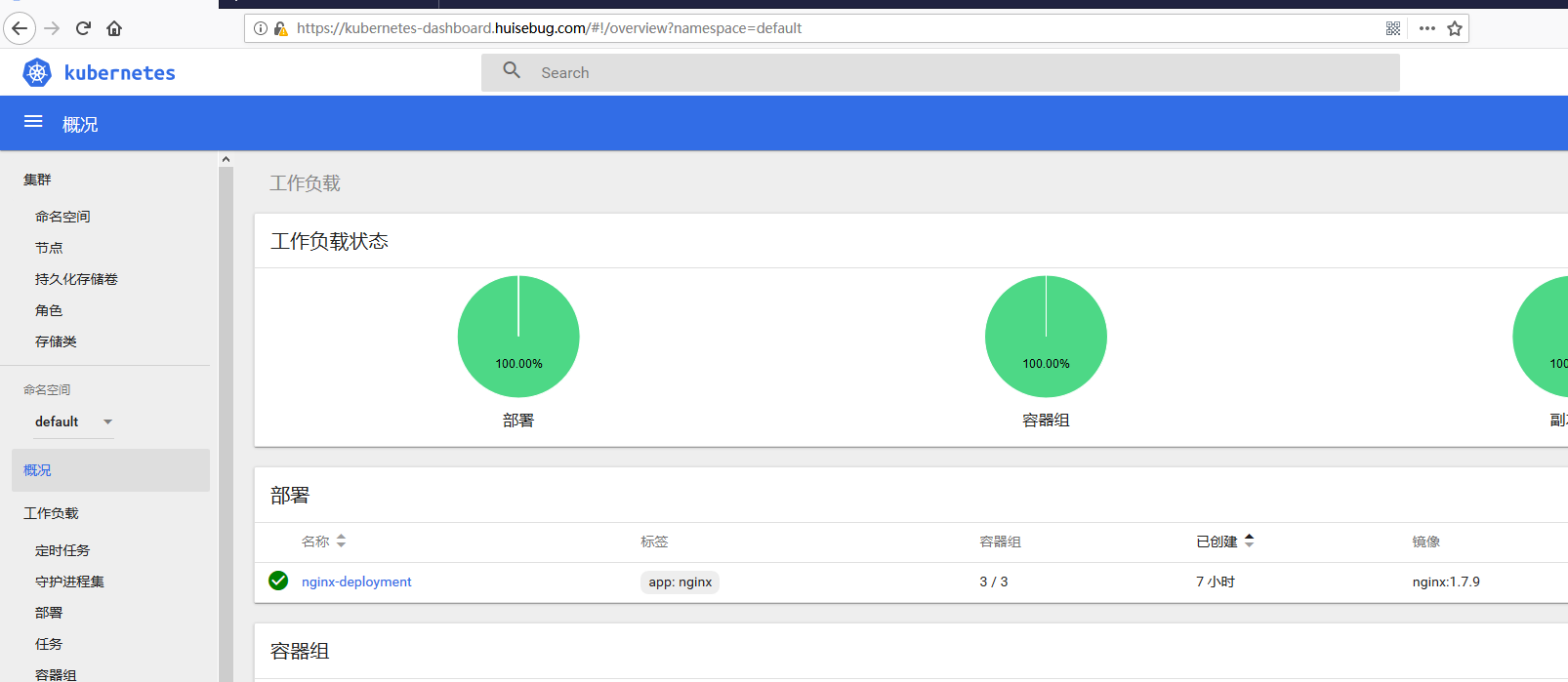
验证效果 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 查看是否成功建立coredns pod $ kubectl get pod --all-namespaces -o wide 查看是否成功建立coredns pod $ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.254.0.1 <none> 443/TCP 16m 可以看到default命名空间下现在就一个service 将之前建立的nginx-deployment暴露为service $ kubectl expose deploy nginx-deployment # 查看 $ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.254.0.1 <none> 443/TCP 16m nginx-deployment ClusterIP 10.254.136.63 <none> 80/TCP 3s
测试能否解析成对应的IP地址
1 kubectl exec -it nginx-deployment-5c689d88bb-2mzx4 ping nginx-deployment
测试不同命名空间
1 kubectl get svc --all-namespaces
1 kubectl exec -it nginx-deployment-5c689d88bb-2mzx4 ping calico-typha.kube-system
至此,coredns安装完成。
再次验证整个集群的proxy负载机制效果
Helm 相当于centos的yum,Ubuntu的apt-get命令
此处安装的helm是2.12.2版本,之前的2.6版本在安装后续的chart会出现:
Error: parse error in *** function “genCA” not defined 错误
Helm client安装 1 2 3 4 5 # 下载 $ wget https://storage.googleapis.com/kubernetes-helm/helm-v2.12.2-linux-amd64.tar.gz # 解包并将二进制文件helm拷贝到/usr/local /bin目录下 $ tar -zxvf helm-v2.12.2-linux-amd64.tar.gz && mv linux-amd64/helm /usr/local /bin/helm
安装socat 用于端口转发,在准备初始环境安装keepalived已经安装,必须在所有Node服务器安装
Helm server安装 创建tiller的 serviceaccount 和 clusterrolebinding
1 2 kubectl create serviceaccount --namespace kube-system tiller kubectl create clusterrolebinding tiller-cluster-rule --clusterrole=cluster-admin --serviceaccount=kube-system:tiller
然后安装helm服务端tiller
1 helm init --upgrade -i registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.12.2 --stable-repo-url https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
修改serviceAccount :
1 kubectl patch deploy -n kube-system tiller-deploy -p '{"spec":{"template":{"spec":{"serviceAccount":"tiller"}}}}'
检查是否安装成功,等待一段时间后。
Traefik k8s集群中的http反向代理服务
直接下载官方的charts,然后找到traefik就可以执行安装了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 $ git clone <https://github.com/helm/charts.git> # 安装 $ cd charts/stable/traefik # 执行默认配置,显然是不符合我这里的需求。 $ helm install . # 列出helm安装的资源类型 $ helm ls NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE gilded-skunk 1 Fri Jan 18 10:36:42 2019 DEPLOYED traefik-1.59.0 1.7.6 default # 删除helm安装的资源类型 $ helm delete gilded-skunk --purge release "gilded-skunk" deleted # 安装我想要的一些功能 # 默认的template目录下的deployment.yaml文件没有开启hostNetwork: true ,执行下面语句开启(主要是我这儿环境配置了hostPort不生效,(因为CNI插件的原因)配置hostNetwork就生效) $ cd /root/charts/stable/traefik/templates $ Lnum=$(sed -n '/spec/=' deployment.yaml |sed -n "2" p) # 下面的格式为sed -ie 单引单引双引变量名双引单引a六个空格hostNetwork: true 单引 deployment.yaml $ sed -ie & # 中间是6个空格,不能少也不能多
也可以参考我已经修改好的charts,参考地址:https://github.com/huisebug/k8s1.12-Ecosphere/tree/master/Traefik
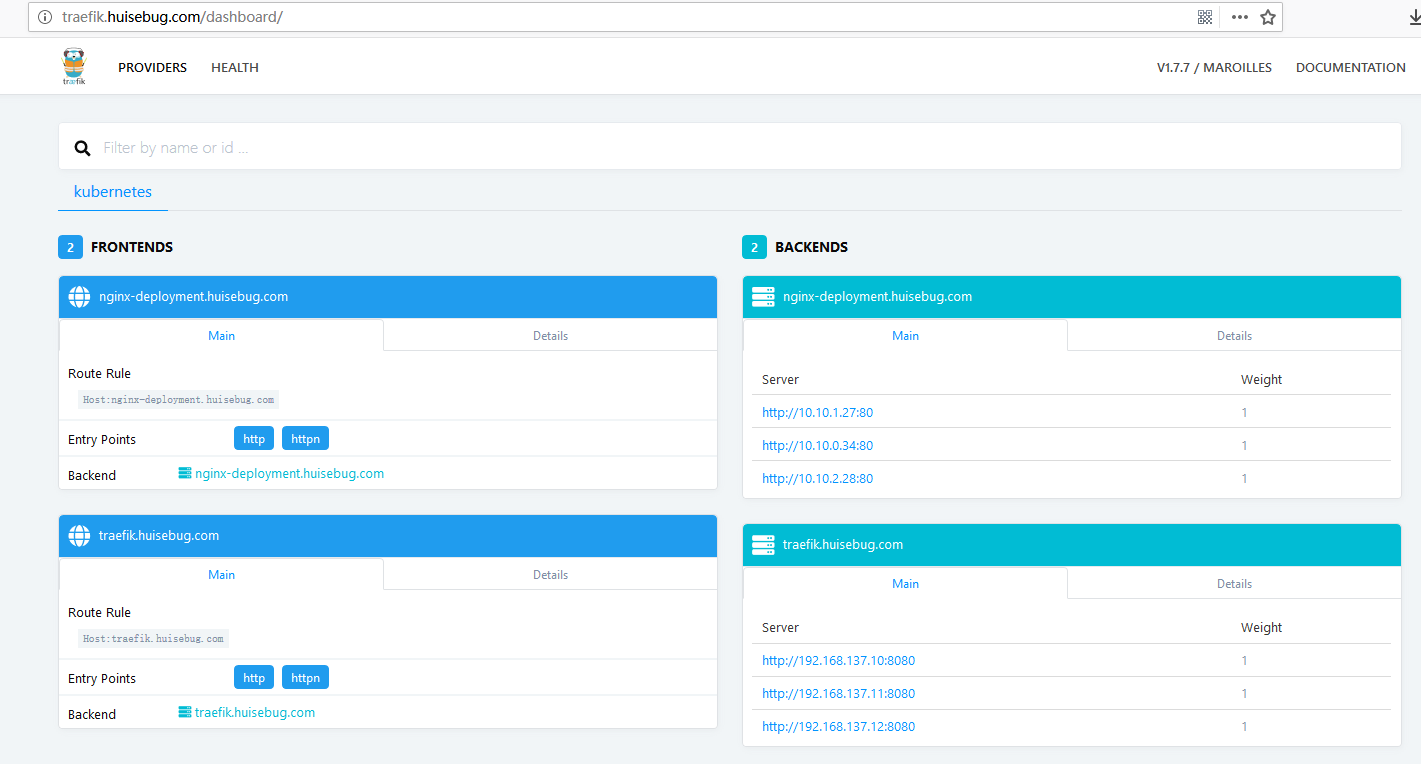
安装traefik 1 2 3 4 5 6 $ helm delete traefik --purge $ helm install --name traefik --namespace kube-system \ --set replicas=3,cpuLimit=1000m,memoryLimit=1Gi,rbac.enabled=true ,\ dashboard.enabled=true ,dashboard.domain=traefik.huisebug.com,\ metrics.prometheus.enabled=true \ /root/charts/stable/traefik
确保服务已经运行
重启服务器后如果traefik没有正确启动,那就删除后重新建立。
验证效果 之前我们验证coredns时候将一个nginx暴露为service,现在建立一个ingress来对应这个service
1 kubectl get svc --all-namespaces
参考yaml地址
1 kubectl apply -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/Traefik/nginx-ingress.yaml
在本地解析文件中追加域名解析
访问验证效果
至此,traefik安装完成
Dashboard 会额外建立一个名称为anonymous-dashboard-proxy的 Cluster Role(Binding)来让system:anonymous这个匿名使用者能够通过 API Server 来 proxy 到 KubernetesDashboard,而这个 RBAC规则仅能够存取services/proxy资源,以及https:kubernetes-dashboard:资源名称同时在1.7 版本以后的 Dashboard 将不再提供所有权限,因此需要建立一个 service account来绑定 cluster-admin role
具体yaml参考
1 kubectl apply -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/Dashboard/dashboard.yaml
访问验证
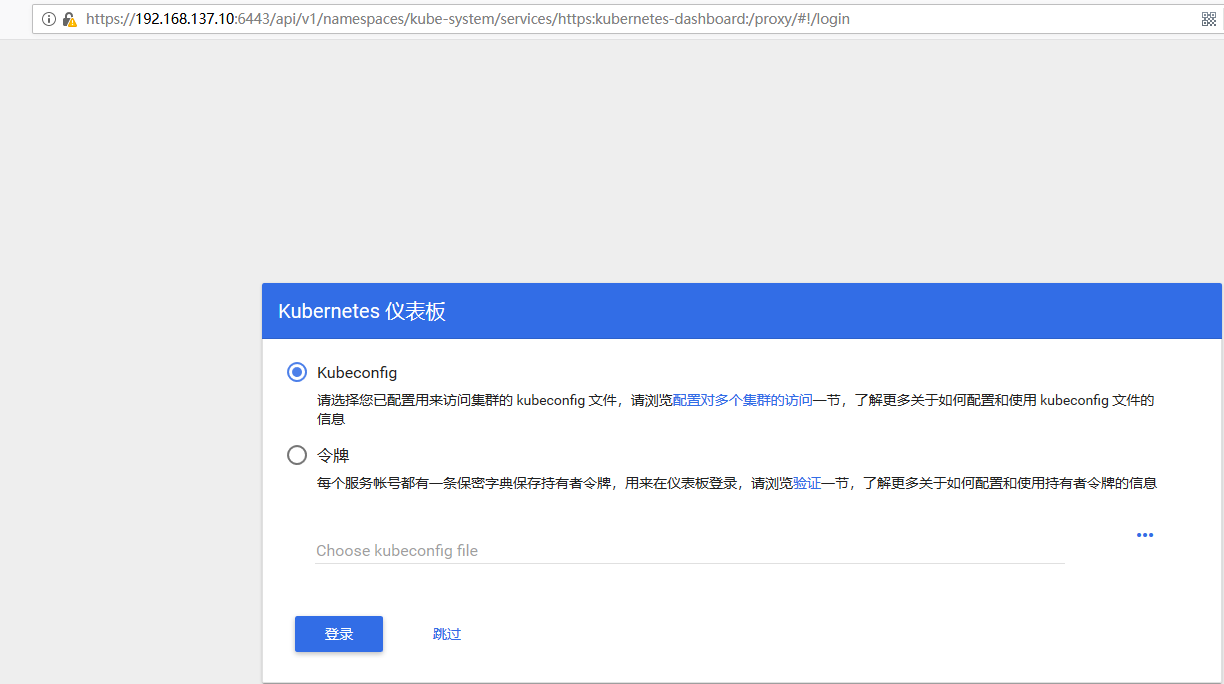
方式一:可以通过浏览器读取Dashboard
方式二:ingress既然上述我们已经搭建了traefik,所以我们建立一个ingress来访问。
直接https访问方式 导⼊证书 将⽣成的admin.pem证书转换格式(/etc/kubernetes/ssl目录下)
1 2 cd /etc/kubernetes/ssl openssl pkcs12 -export -in admin.pem -out admin.p12 -inkey admin-key.pem
将⽣成的 admin.p12
访问 这里不能写成VIP+代理端口来跳转,我们三台服务器都安装了api-server,可以任意如下一个访问
https://192.168.137.10:6443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/
https://192.168.137.11:6443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/
https://192.168.137.12:6443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/
成功向浏览器导入证书后访问成功效果
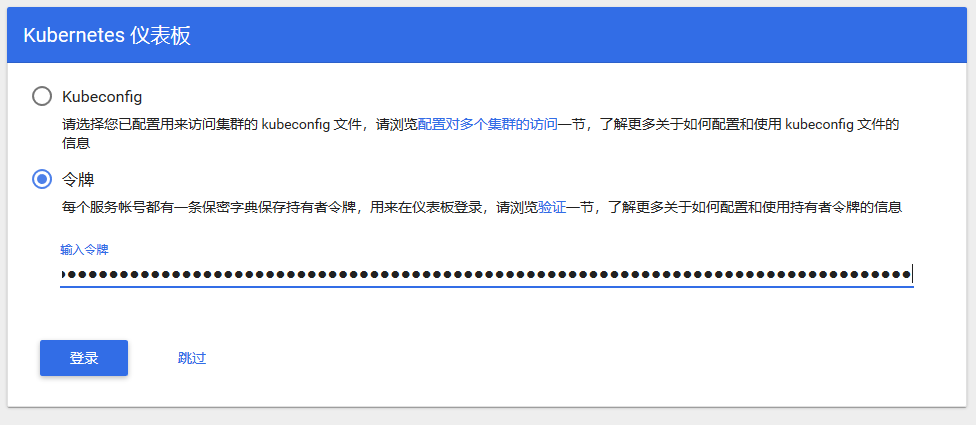
使用令牌(token)进行访问
令牌获取。
$ kubectl -n kube-system describe secrets | sed -rn "/sdashboard-token-/,/^token/{/^token/s#S+s+##p}"
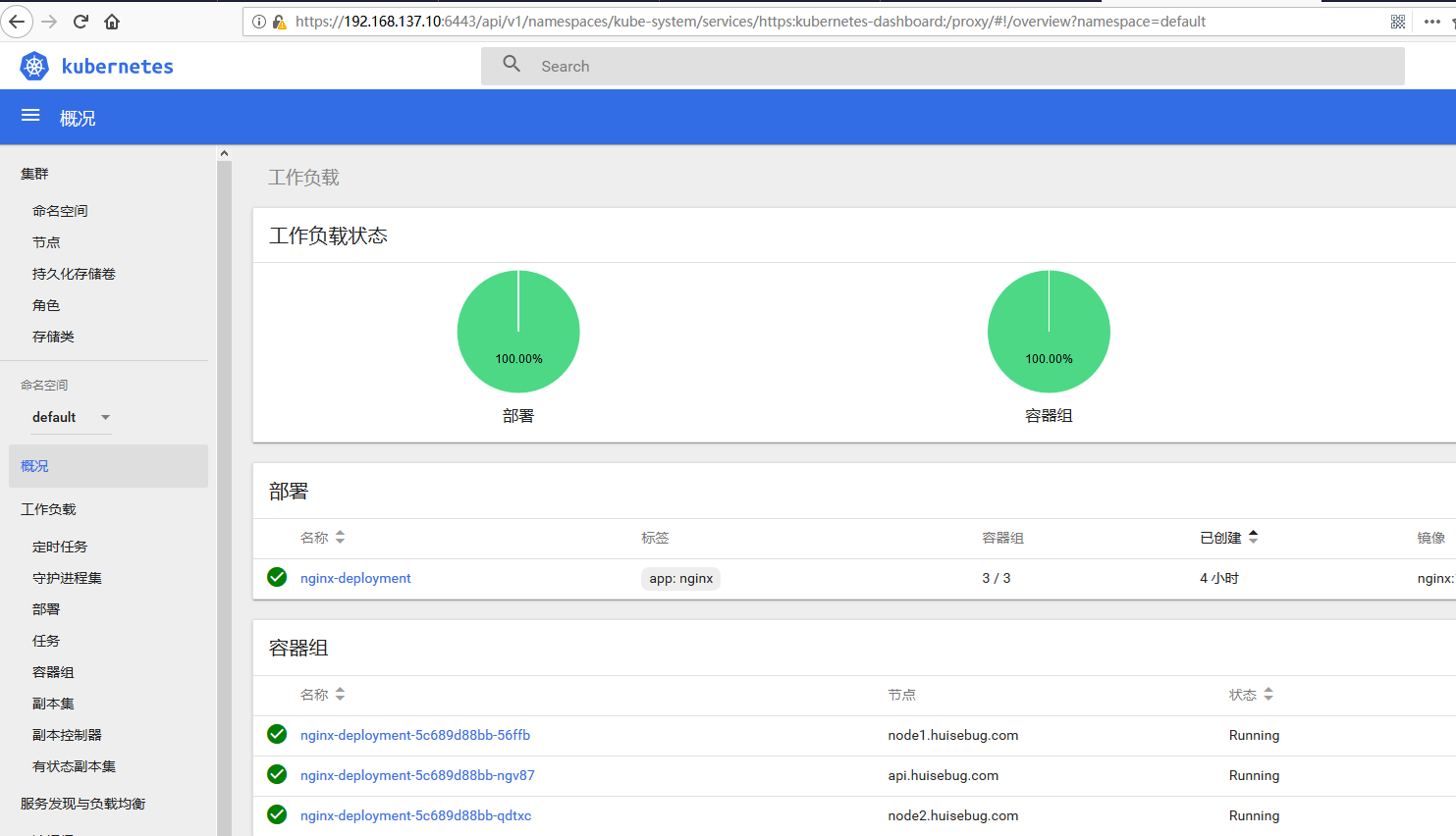
将token值复制到令牌一栏即可成功访问dashboard
ingress方式 参考yaml文件地址
1 kubectl apply -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/Dashboard/kubernetes-dashboard-ingress.yaml
这里我们需要开启traefik的https功能,并且开启ssl.insecureSkipVerify=true跳过验证SSL连接上的证书,如果不开启此处,就无法使用ingress进行访问。此处是相当于使用了https连接,没有进行证书验证。
1 2 3 4 5 6 7 8 helm delete traefik --purge helm install --name traefik --namespace kube-system \ --set imageTag=1.6.5,replicas=3,\ cpuLimit=1000m,memoryLimit=1Gi,rbac.enabled=true,\ dashboard.enabled=true,dashboard.domain=traefik.huisebug.com,\ metrics.prometheus.enabled=true,\ ssl.enabled=true,ssl.insecureSkipVerify=true \ /root/charts/stable/traefik
如果出现traefik出现问题就降低配置中的traefik镜像版本。
验证访问效果
Scope监控 用于监控整个k8s集群的网络TOP
安装scope 直接使用官方yaml
1 kubectl apply -f "https://cloud.weave.works/k8s/scope.yaml?k8s-version=$(kubectl version | base64 | tr -d '\n')"
注意上面的namespace是weave
暴露访问两种方式 Service的nodeport方式 1 2 3 4 5 6 7 8 9 10 11 wget https://cloud.weave.works/k8s/scope.yaml # 修改service的值 spec: type: NodePort ports: - name: app port: 80 protocol: TCP targetPort: 4040 nodePort: 30040
注意:Nodeport只能暴露30000到32767,不然会报错如下:
The Service “weave-scope-app” is invalid: spec.ports[0].nodePort: Invalid value:
Traefik代理 编写一个ingress
1 2 参考yaml地址 kubectl create -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/Scope/scope-ingress.yaml
验证效果
EFK 此栏目已经迁移到gluster-heketi-efk
Prometheus-operator 此栏目已经迁移到Prometheus-operator
Nginx-ingress 同样的是整个集群的反向代理,可支持四层代理
此处安装是建立在prometheus-operator的基础上的。
直接下载官方的charts,然后找到traefik就可以执行安装了
1 git clone <https://github.com/helm/charts.git>
详细参数介绍请参考官方地址https://github.com/helm/charts/tree/master/stable/nginx-ingress#configuration
具体的镜像下载
1 2 3 4 5 docker pull mirrorgooglecontainers/defaultbackend:1.4 docker tag mirrorgooglecontainers/defaultbackend:1.4 k8s.gcr.io/defaultbackend:1.4 docker pull huisebug/sec_re:nginx-ingress-controller-0.21.0 docker tag huisebug/sec_re:nginx-ingress-controller-0.21.0 quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.21.0
安装nginx-ingress 首先需要删除traefik
1 2 helm delete traefik --purge helm delete nginx-ingress --purge
官方的可配置参数各种坑不断,不推荐用命令行参数,直接修改values.yaml比较方便。下面是我修改的参数值:
部署类型为daemonset
开启hostNetwork功能
资源配额
更改service type: LoadBalancer为ClusterIP
rbac开启
serviceAccount名称为nginx-ingress-controller
开启metrics
开启servicemonitor,设置namespace为monitoring便于prometheus-operator监控
部署https://github.com/huisebug/k8s1.12-Ecosphere/blob/master/nginx-ingress/valuesdaemonset.yaml
1 2 3 helm delete nginx-ingress --purge helm install --name nginx-ingress --namespace kube-system /root/charts/stable/nginx-ingress -f /root/charts/stable/nginx-ingress/valuesdaemonset.yaml
验证效果
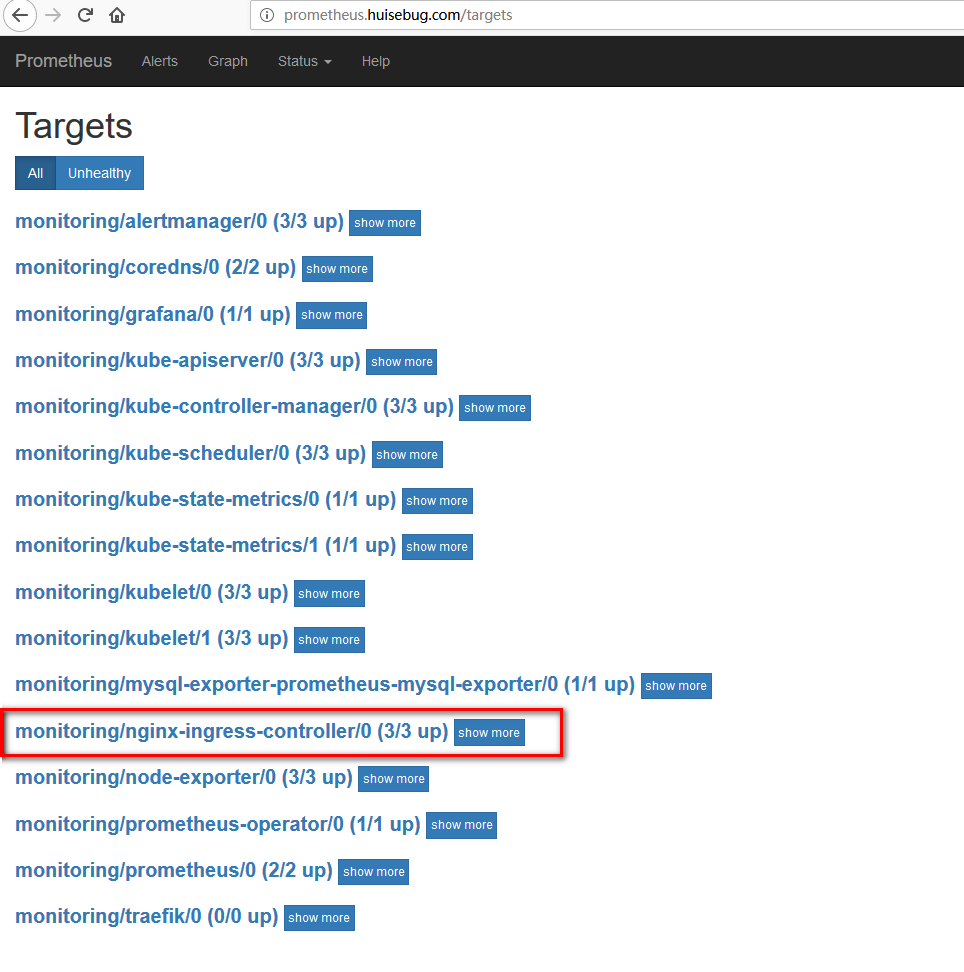
访问prometheus查看是否添加了nginx-ingress-controller的metrics
如何验证默认后端(nginx-ingress-default-backend)效果呢?
首先我们在本地hosts文件中建立一个整个k8s集群中没有定义ingress,不存在的域名并指向nginx-ingress-controller,访问测试即可
访问测试
也可以参考我已经修改好的charts,参考地址:https://github.com/huisebug/k8s1.12-Ecosphere/tree/master/nginx-ingress
nginx-ingress-controller nginx功能 nginx-ingress-controller 并不像traefik一样提供WEB界面功能
nginx-ingress-controller-ingress.yamlhttps://github.com/huisebug/k8s1.12-Ecosphere/blob/master/nginx-ingress/ingress.yaml
验证效果,这个返回的页面是nginx-ingress-controller返回的,并不是后端返回的
nginx-ingress-controller的四层代理 nginx从1.9.0开始,新增加了一个stream模块,用来实现四层协议的转发、代理或者负载均衡等。可以配置TCP或者UDP来实现这个功能
代理集群的coredns 只需要在values.yaml文件中增加UDP协议端口:coredns的service名:service_IP
重新建立nginx-ingress-controller后,查看是否成功开启UDP 53端口
集群完整的域名如何获取?
我们使用一个pod去ping另一个pod的service名称,kube-dns会解析出完整的域名,就可以修改其中的service名和对应的namespace即可
验证效果
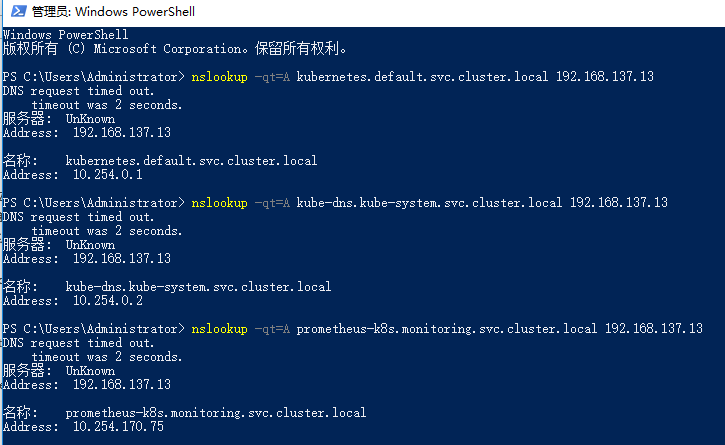
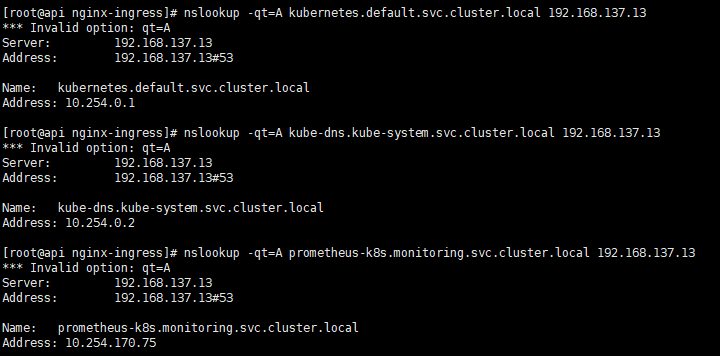
1 2 3 nslookup -qt=A kubernetes.default.svc.cluster.local 192.168.137.13 nslookup -qt=A kube-dns.kube-system.svc.cluster.local 192.168.137.13 nslookup -qt=A prometheus-k8s.monitoring.svc.cluster.local 192.168.137.13
windows CMD验证
linux 验证
Metrics-server kubernetes Metrics Server是资源使用数据的集群范围聚合器,是Heapster的后继者。度量服务器通过汇集来自kubernetes.summary_api的数据来收集节点和pod的CPU和内存使用情况。摘要API是一种内存高效的API,用于将数据从Kubelet / cAdvisor传递到度量服务器。
从 v1.8 开始,资源使用情况的度量(如容器的 CPU 和内存使用)可以通过 Metrics API获取。注意:
Metrics API 只可以查询当前的度量数据,并不保存历史数据
Metrics API URI 为 /apis/metrics.k8s.io/,在 k8s.io/metrics 维护
必须部署 metrics-server 才能使用该 API,metrics-server 通过调用 Kubelet Summary API 获取数据
在新版本的kubernetes中 Pod CPU使用率不在来源于heapster,而是来自于metrics-server
支持metrics-server必须在api-server中添加如下参数
设置apiserver相关参数
1 2 3 4 5 6 7 --requestheader-client-ca-file=/etc/kubernetes/ssl/front-proxy-ca.pem --proxy-client-cert-file=/etc/kubernetes/ssl/front-proxy-client.pem --proxy-client-key-file=/etc/kubernetes/ssl/front-proxy-client-key.pem --requestheader-allowed-names=aggregator --requestheader-group-headers=X-Remote-Group --requestheader-extra-headers-prefix=X-Remote-Extra- --requestheader-username-headers=X-Remote-User
部署metrics-server 此处将metrics-server放到prometheus-operator后面是因为在prometheus-operator建立的时候就建立了一个以prometheus-adapter为支持的api:metrics.k8s.io ,这个api建立后就可以使用kubectl top命令了,但是prometheus-operator方式建立的api:metrics.k8s.io 仅仅支持kubectltop pod,并不支持kubectl top node。api:custom.metrics.k8s.io 使用prometheus-adapter来作服务支撑和使用metrics-server来建立api:metrics.k8s.io ,我们需要移除prometheus-operator以prometheus-adapter为支持的api:metrics.k8s.io
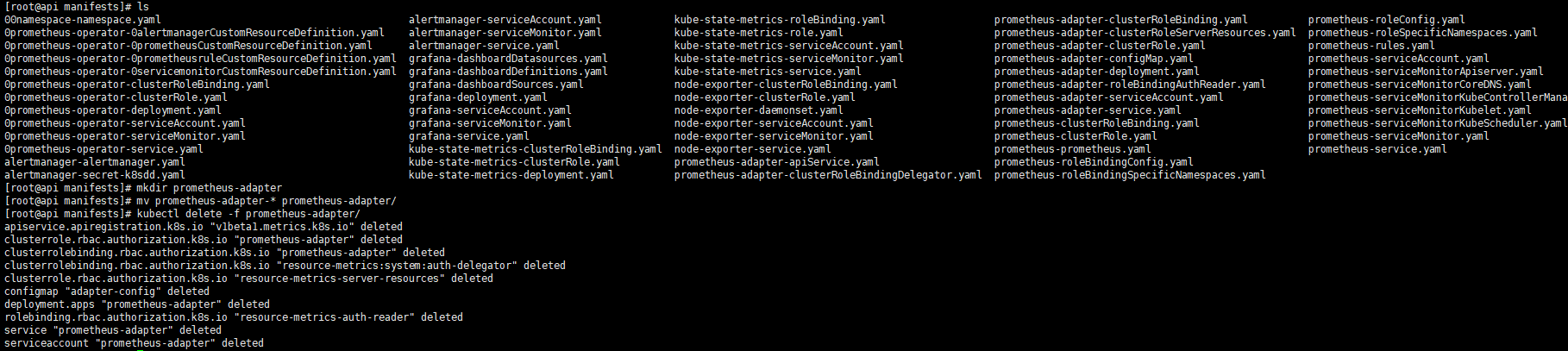
将prometheus-adapter的所有yaml文件归档到一个文件目录中
1 2 3 mkdir prometheus-adapter mv prometheus-adapter-* prometheus-adapter/ kubectl delete -f prometheus-adapter/
然后部署metrics-server,具体部署yaml参考地址
1 kubectl apply -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/Metrics-server1.12/Metrics-server1.12.yaml
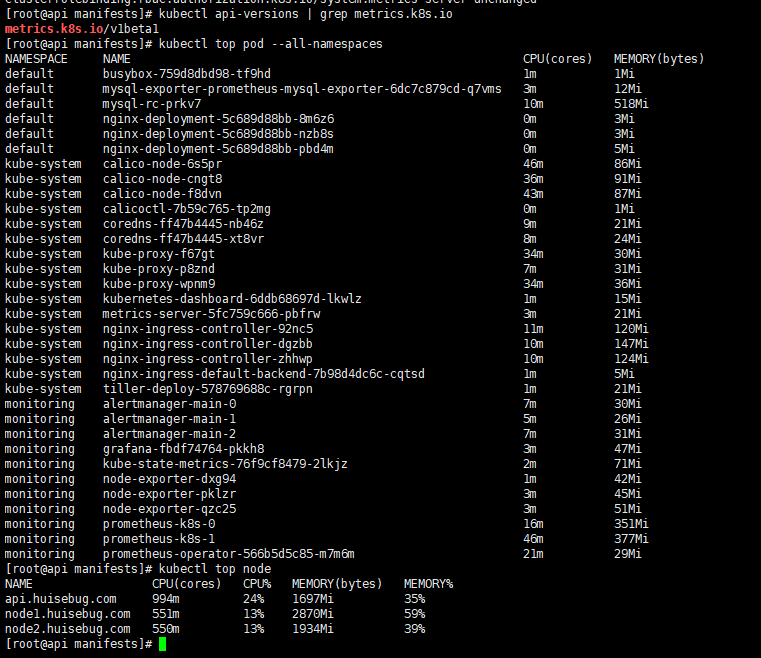
验证效果 获取命令。
1 2 3 $ kubectl api-versions | grep metrics.k8s.io $ kubectl top pod --all-namespaces $ kubectl top node
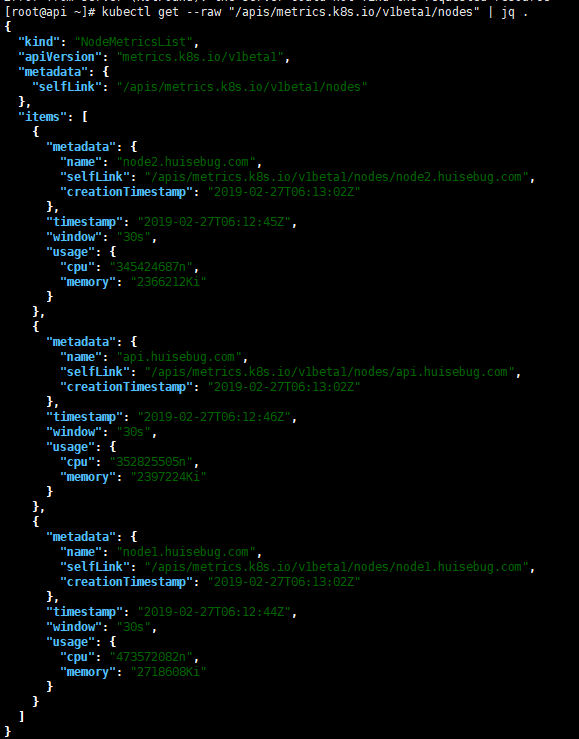
查看nodes metrics:
1 kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
HPA 此栏目已经迁移到k8s-HPA


















 wechat
wechat alipay
alipay





