
Prometheus-Operator监控k8s
这是一篇Prometheus-Operator监控k8s服务的部署、监控原理讲解、监控配置、告警模板配置。
初始条件:
- K8s1.12+集群
Prometheus-operator
安装monitoring.coreos.com/v1 api(prometheus-operator)
此处我们直接使用yaml文件方式安装,不使用helm安装,helm安装会缺少一些服务,不方便我们更深了解
1 | git clone https://github.com/coreos/prometheus-operator.git |
已迁移到如下
1 | git clone https://github.com/coreos/kube-prometheus.git |

1 | kubectl get pod --all-namespaces |
如果整个集群是否设置tain,解除即可
1 | for i in api.huisebug.com node1.huisebug.com node2.huisebug.com; do kubectl taint nodes $i node-role.kubernetes.io/master:NoSchedule-; done |
集群状态
查看是否建立并启动好所有容器
1 | kubectl get pod --all-namespaces -o wide 或者 kubectl get pod -n monitoring |
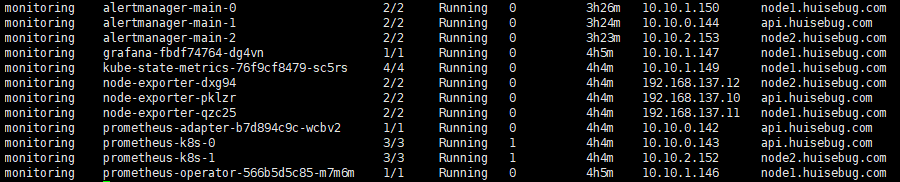
问题汇总
- Prometheus can’t access node-exporter and kube-state-metrics
解决地址
https://github.com/coreos/prometheus-operator/issues/2330
- alertmanager无法建立pod,主要是服务器环境硬件跟不上
解决地址
https://github.com/coreos/prometheus-operator/issues/1902
https://github.com/coreos/prometheus-operator/issues/965
- prometheus的storage.local.retention(数据存储时间)设置更长时间
解决地址
https://github.com/coreos/prometheus-operator/issues/732
只需在prometheus-prometheus.yaml文件中增加一行配置
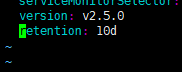
主要介绍一下alertmanager无法建立pod的问题的解决方法,默认的alertmanager重启嗅探如下:
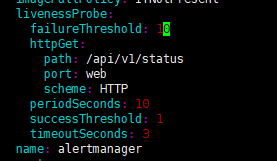
即嗅探10*10=100秒以后就会重启,显然模拟环境是无法在100秒内成功启动alertmanager,所以这里我们需要给配置文件alertmanager-alertmanager.yaml添加paused:true参数,添加步骤如下:
- 首先已经建立所有的prometheus-operator服务(kubectl apply -f manifests/ )
- 然后给alertmanager-alertmanager.yaml添加paused: true参数; paused: true参数解释参考地址:https://github.com/coreos/prometheus-operator/blob/master/Documentation/api.md#alertmanagerspec
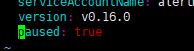
- 重载配置文件alertmanager-alertmanager.yaml (kubectl apply -f alertmanager-alertmanager.yaml)
- 将配置文件alertmanager-alertmanager.yaml建立后生成的statefulset转储到文件中(kubectl get statefulsets alertmanager-main -n monitoring -o yaml > alertmanager-main-statefulsets.yaml)
- 在集群中删除alertmanager(kubectl delete -f alertmanager-main-statefulsets.yaml)
- 修改文件alertmanager-main-statefulsets.yaml的嗅探失败次数,修改为30次,即30*10=300秒,也可根据你的实际环境来调节
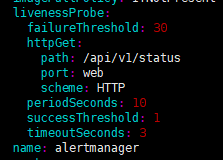
- 再次创建,即可成功建立alertmanager
解析prometheus-operator原理
新加了两个apiversion,获取命令:
1 | kubectl api-versions |
metrics.k8s.io/v1beta1
monitoring.coreos.com/v1
- monitoring.coreos.com/v1是作为四个资源对象的组而添加到api中
- metrics.k8s.io/v1beta1是使用资源对象APIService进行建立的,这个apiversion需关联到service对应的pod prometheus-adapter建立成功才会成功建立,所以记住需要使用kubectl api-versions命令关注是否建立成功
使用自定义资源定义CustomResourceDefinitions(CRD)新增4个kind:
- Prometheus,它定义了所需的Prometheus部署。运营商始终确保正在运行与资源定义匹配的部署。
- ServiceMonitor,以声明方式指定应如何监控服务组。操作员根据定义自动生成Prometheus刮削配置。
- PrometheusRule,它定义了一个所需的Prometheus规则文件,该文件可以由包含Prometheus警报和记录规则的Prometheus实例加载。
- Alertmanager,它定义了所需的Alertmanager部署。运营商始终确保正在运行与资源定义匹配的部署。
获取命令如下
1 | kubectl get Servicemonitor --all-namespaces |
yaml类型
- 0prometheus-operator*:建立整个prometheus-operator的CRD、提供服务支持的pod运行
- alertmanager*:prometheus所需的告警处理,alertmanager告警的pod建立
- grafana*:监控页面展示
- kube-state-metrics*:增加对deployment建立的pod、statefulset建立的pod等资源对象的metrics数据,参考地址:https://github.com/kubernetes/kube-state-metrics
- node-exporter*:运行k8s集群的node的服务器数据抓取
- prometheus-adapter:为metrics.k8s.io/v1beta1提供metrics数据支持,获取集群的node和pod的CPU、内存使用情况,但是在这里只能获取到pod的,无法获取node的,后续将会在HPA V2章节讲解如何解决。
- prometheus*:prometheus监控系统的pod建立,为需要添加到监控列表的服务增加metrics
简易原理
数据源是从prometheus获取的,那么prometheus是如何获取k8s中这些数据的呢?
- 资源类型ServiceMonitor来定义添加的要被监控的k8s的服务service,然后使用operator工具来定义一个资源类型Prometheus进行筛选ServiceMonitor进行服务监控。PrometheusRule和Alertmanager进行规制和告警设置。
资源类型Prometheus
这里我们来深度解析下这个资源类型为Prometheus
1 | kubectl get Prometheus --all-namespaces -o yaml > k8s-prometheus.yaml |
去除一些不必要的信息后,
1 | apiVersion: v1 |
1 | kind: List |
资源类型PrometheusRule
专门用于prometheus的rules配置,执行以下命令来参照修改
1 | kubectl get prometheusrule prometheus-k8s-rules -n monitoring -o yaml |
后续将会在企业微信告警配置中讲解
资源类型ServiceMonitor
kubectl get Servicemonitor –all-namespaces
以下举例三个不同namespace下的service进行说明
1 | kubectl get Servicemonitor kube-apiserver -n monitoring -o yaml > kube-apiserver-servicemonitor.yaml |
1 | kubectl get Servicemonitor node-exporter -n monitoring -o yaml > node-exporter-servicemonitor.yaml |
1 | kubectl get Servicemonitor coredns -n monitoring -o yaml > coredns-servicemonitor.yaml |
1 | endpoints: #端点配置 |
官方解析地址如下:
https://github.com/coreos/prometheus-operator/blob/master/Documentation/api.md
资源对象Alertmanagers
1 | kubectl get alertmanagers main -n monitoring -o yaml > main-alertmanagers.yaml |
1 | - apiVersion: monitoring.coreos.com/v1 |
使用命令kubectl get statefulsets alertmanager-main -n monitoring -o yaml可以查看到;
验证效果
查看建立的service,我们需要访问prometheus数据源和grafana的监控展示web-UI界面,如何访问呢,可以使用service的Nodeport方式,显然这是非常lose的,这里我使用traefik代理方式(traefik安装就不赘述了),建立ingress
1 | 第一步,查看service |
给客户机的hosts添加本地解析记录
192.168.137.13 prometheus.huisebug.com grafana.huisebug.com
grafana.huisebug.com
grafana.huisebug.com需要密码验证用户名admin 密码admin并提示修改初始密码
grafana已经添加了k8s集群的监控
prometheus.huisebug.com
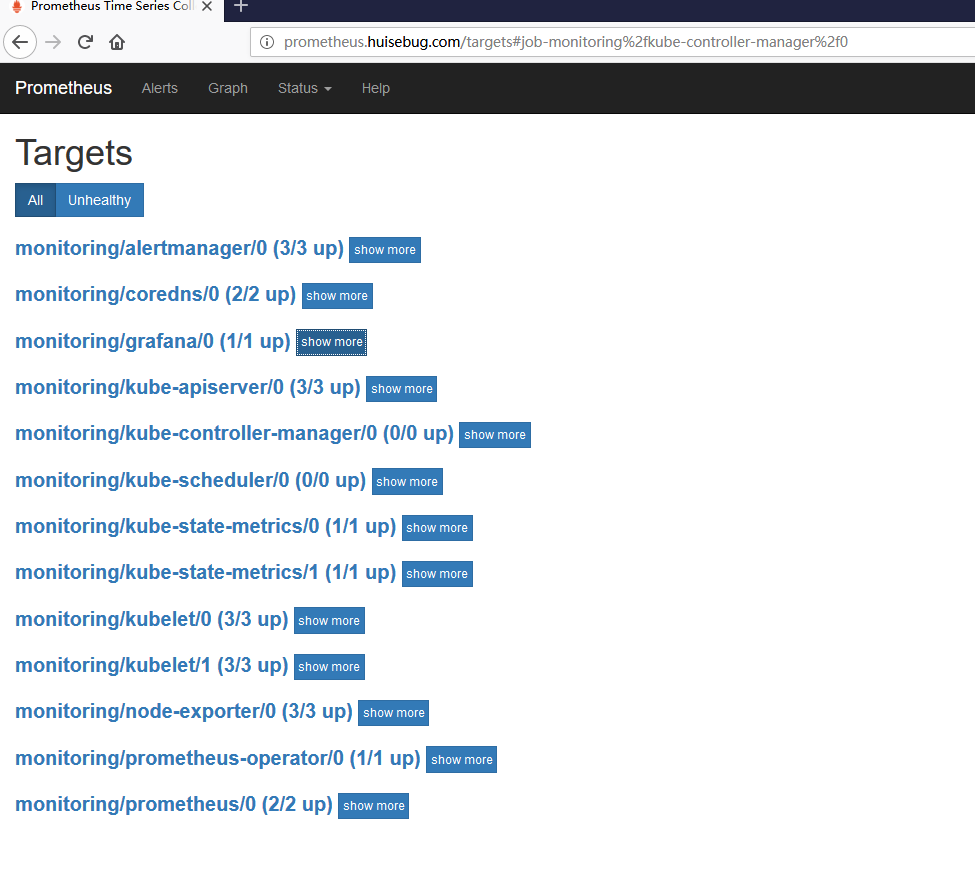
从上面可以看到没有获取到kube-controller-manager、kube-scheduler的metric,接下来就解决这个问题,因为这2个服务不是使用kubeadm方式部署的是使用二进制部署的,所以无法获取到。使用kubeadm方式部署的服务都是存在于namespace:kube-system中,例如:
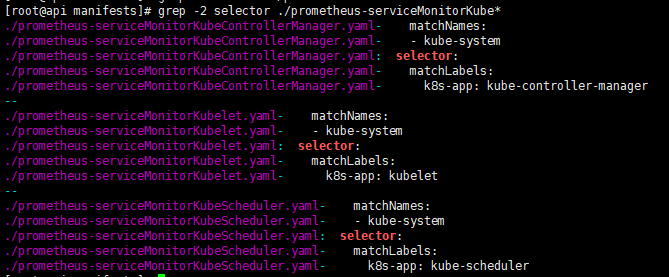
metrics
解决scheduler和controller-manager的metric
想要解决上述问题,先来查看整个集群的service和endpoint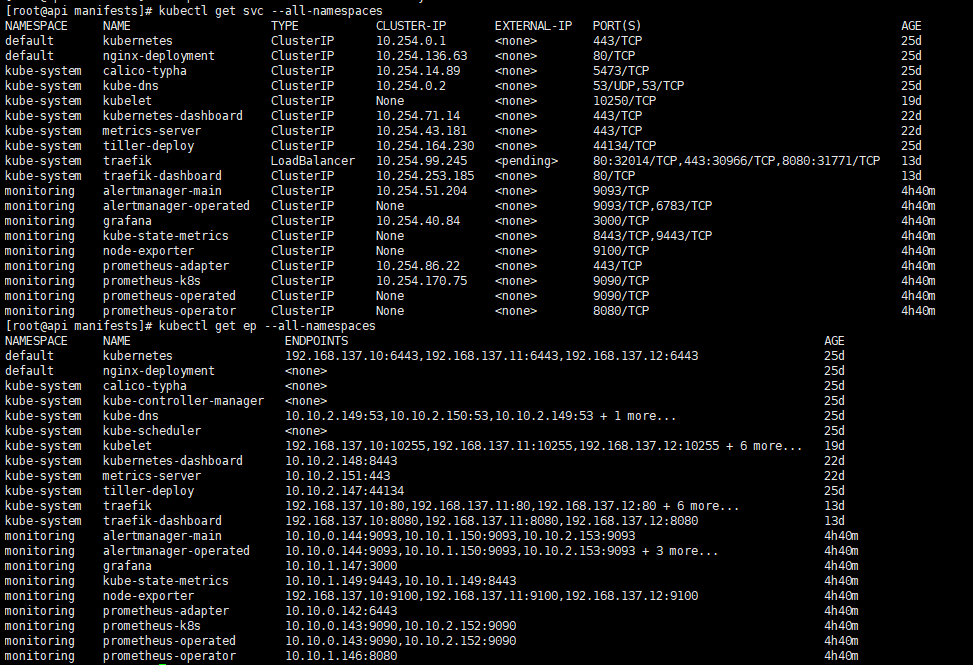
可以看到:
- service中不存在kube-controller-manager、kube-scheduler
- endpoint中都有
所以我们需要建立对应的service和修改endpoint的参数
注意新建立service的port名称要与serviceMonitor配置文件对应的上
参考地址,记得修改其中的地址为你的服务器node_ip地址
1 | kubectl apply -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/Prometheus-operator/metrics/scheduler_controller-manager/metics_services.yaml |
如果建立后还是无法访问记得使用命令netstat -lntp查看端口是否设置是所有网卡可以访问,如果是127.0.0.1,就修改服务的启动参数,设置为0.0.0.0
上述修改完毕后,就可以再次查看是否成功获取到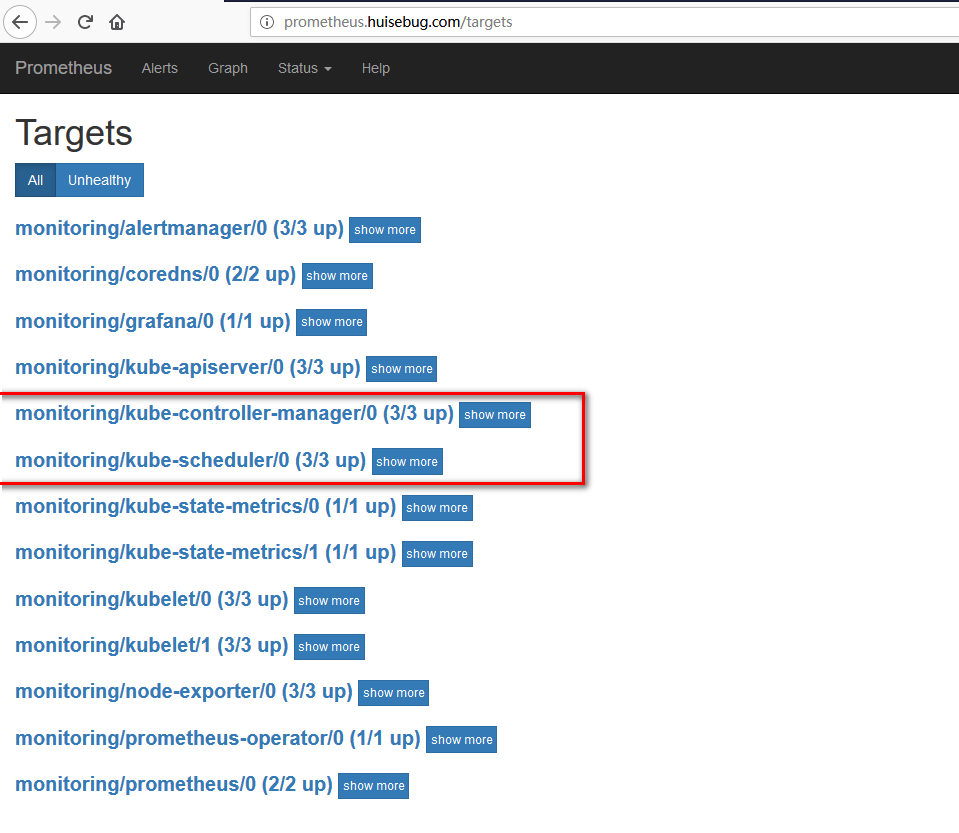
mysql-metrics
此处我们建立一个mysql服务的metric验证
首先建立一个mysql服务
参考地址
1 | kubectl apply -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/Prometheus-operator/metrics/mysql-metrics/mysql-metric.yaml |
测试是否成功建立mysql服务命令
1 | docker run --rm -it mysql sh -c 'exec mysql -h192.168.137.13 -P32306 -pmysql -uroot' |
如果能登录,说明mysql服务已经建立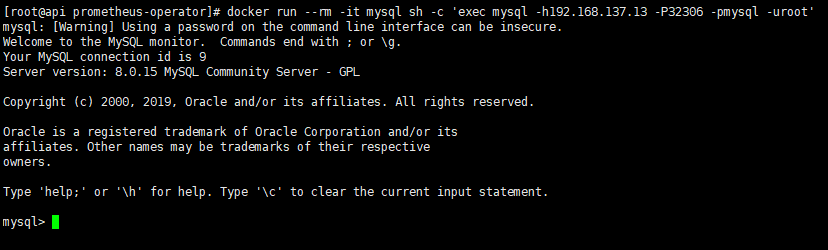
使用helm方式安装mysql-exporter
找到到之前安装traefik的官方charts目录;
进入到stable/prometheus-mysql-exporter目录下就是mysql-exporter的chart了;
values.yaml文件中要指定mysql服务的用户和密码。然后再安装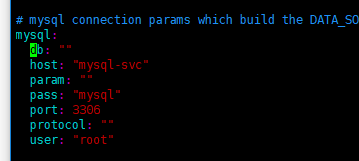
1 | helm install -f values.yaml --name mysql-exporter . |
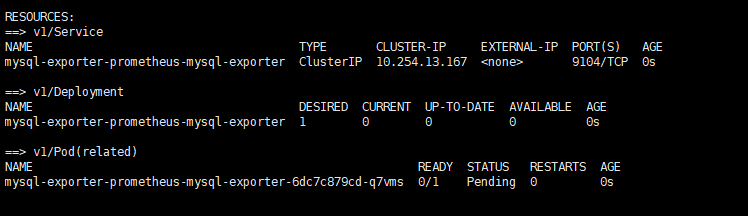
访问mysql-exporter是否有metric生成
这里同样采用traefik代理来访问,建立ingress,上述两个pod都是建立在default命名空间的。
ingress yaml文件参考地址:
1 | https://github.com/huisebug/k8s1.12-Ecosphere/blob/master/Prometheus-operator/metrics/mysql-metrics/mysql-metric.yaml |
本地解析添加
192.168.137.13 mysqlexporter.huisebug.com
验证访问http://mysqlexporter.huisebug.com/metrics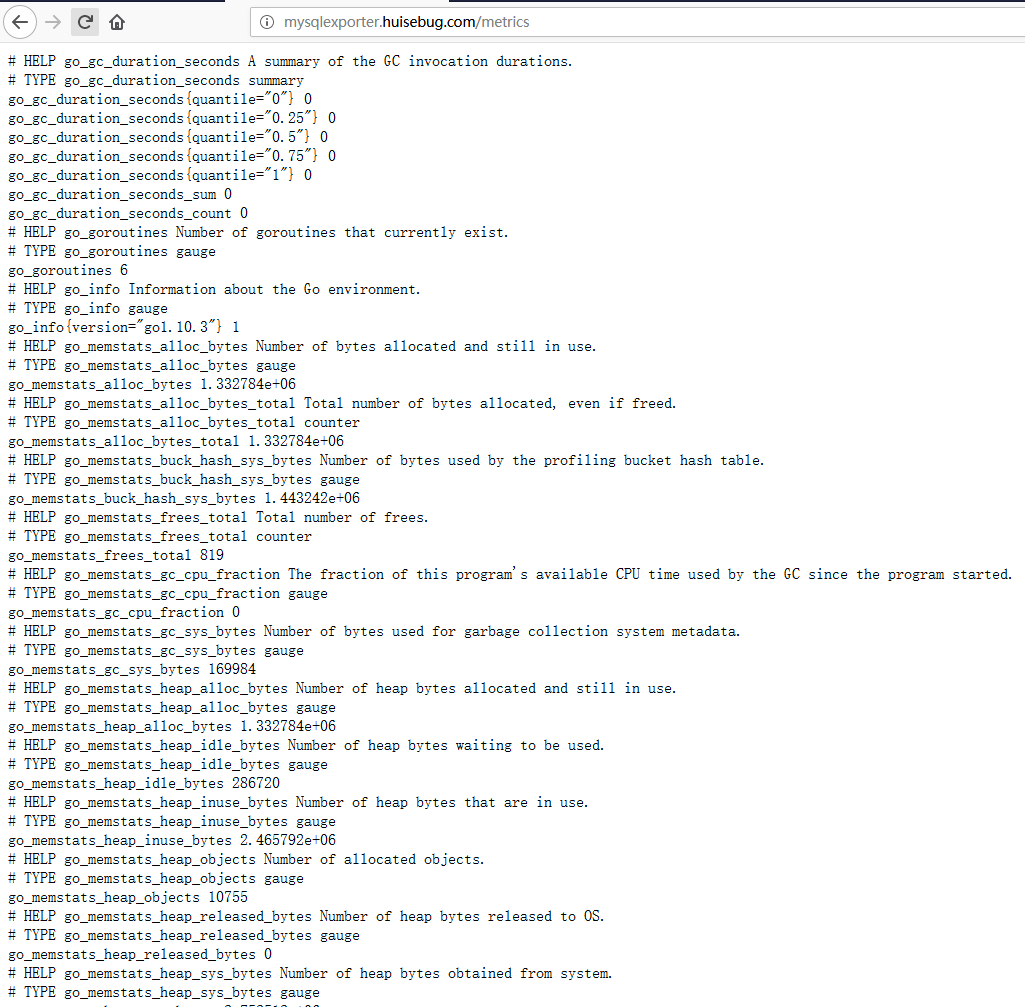
ServiceMonitor资源对象建立
查看service的对应标签,用于servicemonitor
1 | kubectl get svc mysql-exporter-prometheus-mysql-exporter -o yaml| grep -1 labels |

记住servicemonitor必须建立在monitor命名空间下
Prometheus资源对象建立
promethes资源对象在安装monitoring.coreos.com/v1 api的时候建立了一个匹配所有servicemonitot的prometheus资源对象,所以这里我就不建立了,可以参考以下地址:
https://github.com/coreos/prometheus-operator/blob/master/contrib/kube-prometheus/manifests/prometheus-prometheus.yaml
验证效果
再次访问prometheus的target页面查看是否成功获取
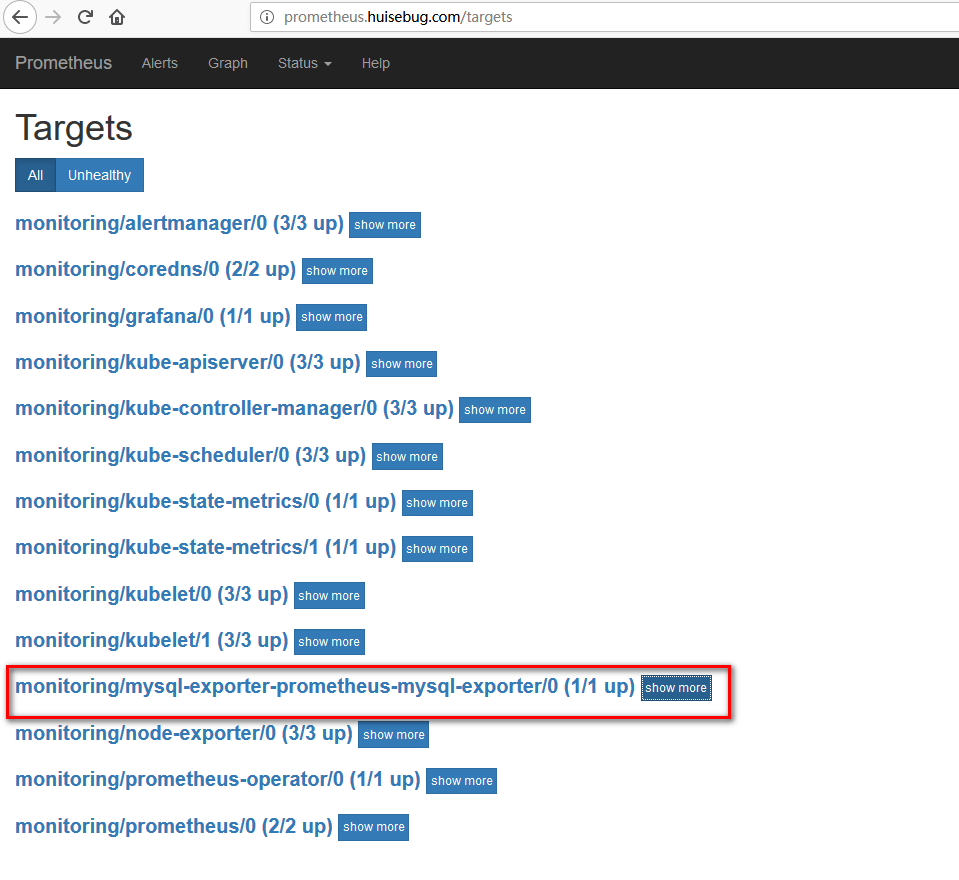
成功建立mysql-metric
traefik-metrics
metrics建立
之前建立traefik的时候开启dashboard.enabled=true,dashboard.domain=traefik.huisebug.com,metrics.prometheus.enabled=true
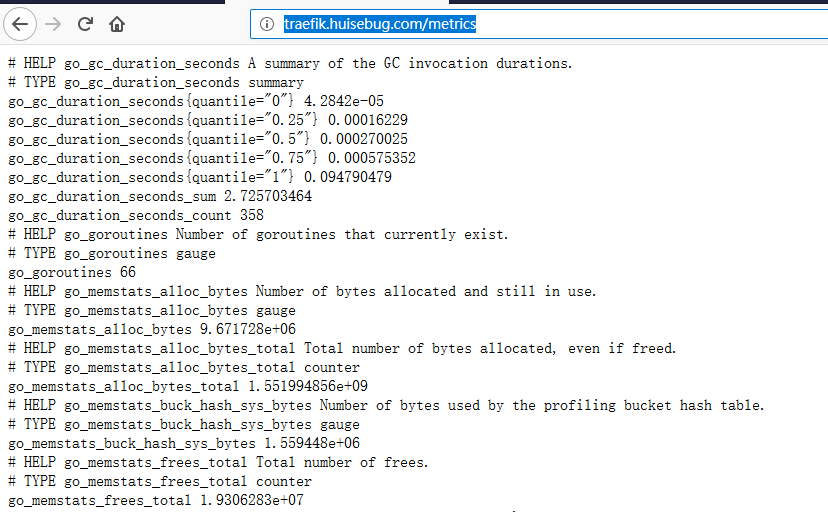
这样我们就可以访问到traefik的metrics
访问地址:http://traefik.huisebug.com/metrics
ServiceMonitor资源对象建立
参考yaml文件
1 | kubectl apply -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/Prometheus-operator/metrics/traefik-metrics/traefik-metrics.yaml |
验证效果

alertmanager告警
alertmanager也是提供了web访问控制台的,先使用ingress进行访问
1 | kubectl apply -f https://raw.githubusercontent.com/huisebug/k8s1.12-Ecosphere/master/Prometheus-operator/alertmanager/alertmanager-ingress.yaml |
记得本地添加解析记录
访问效果
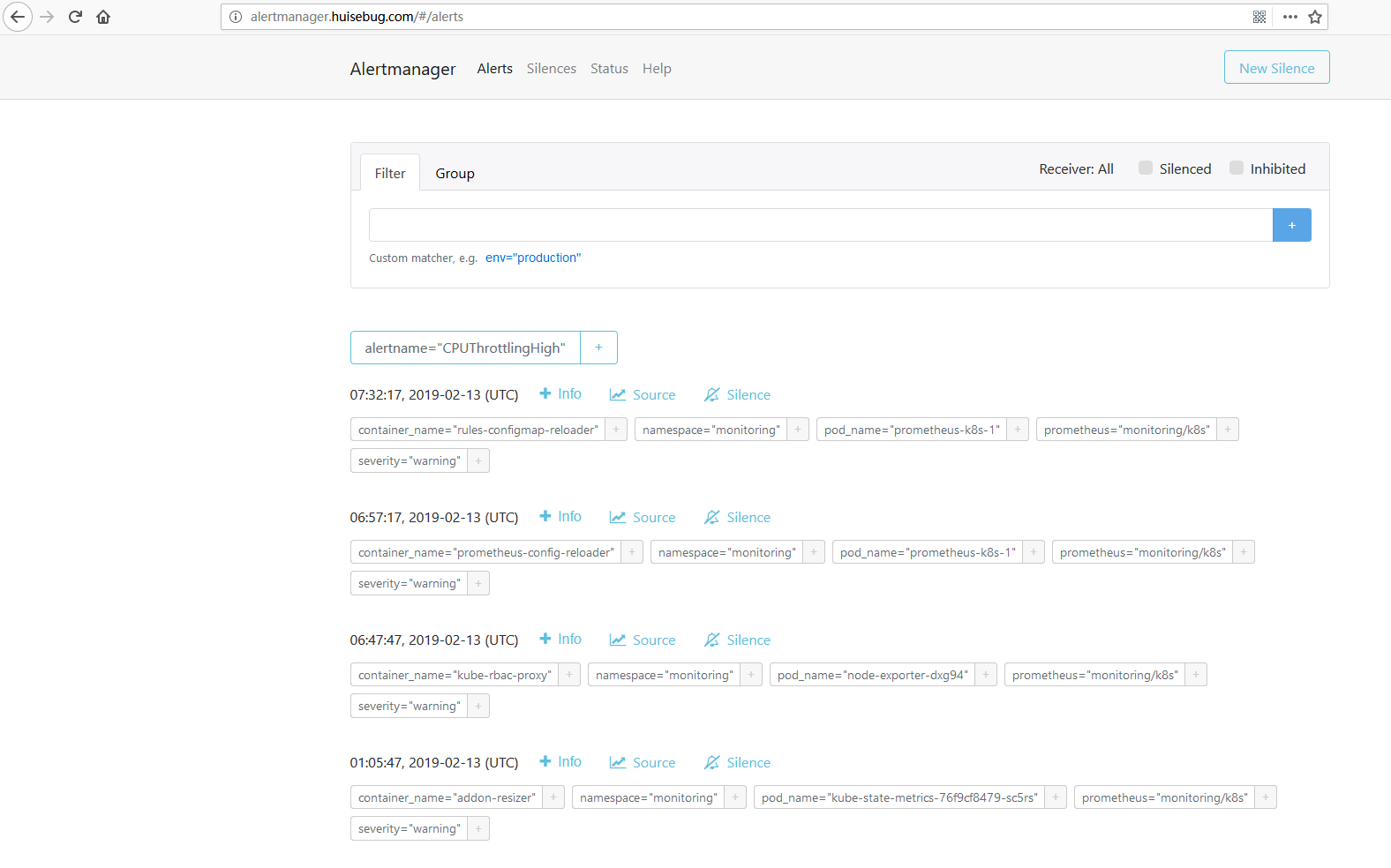
可以看到告警信息这么多,无法找到接收者,所以堆积了。
查看alertmanager的配置参数
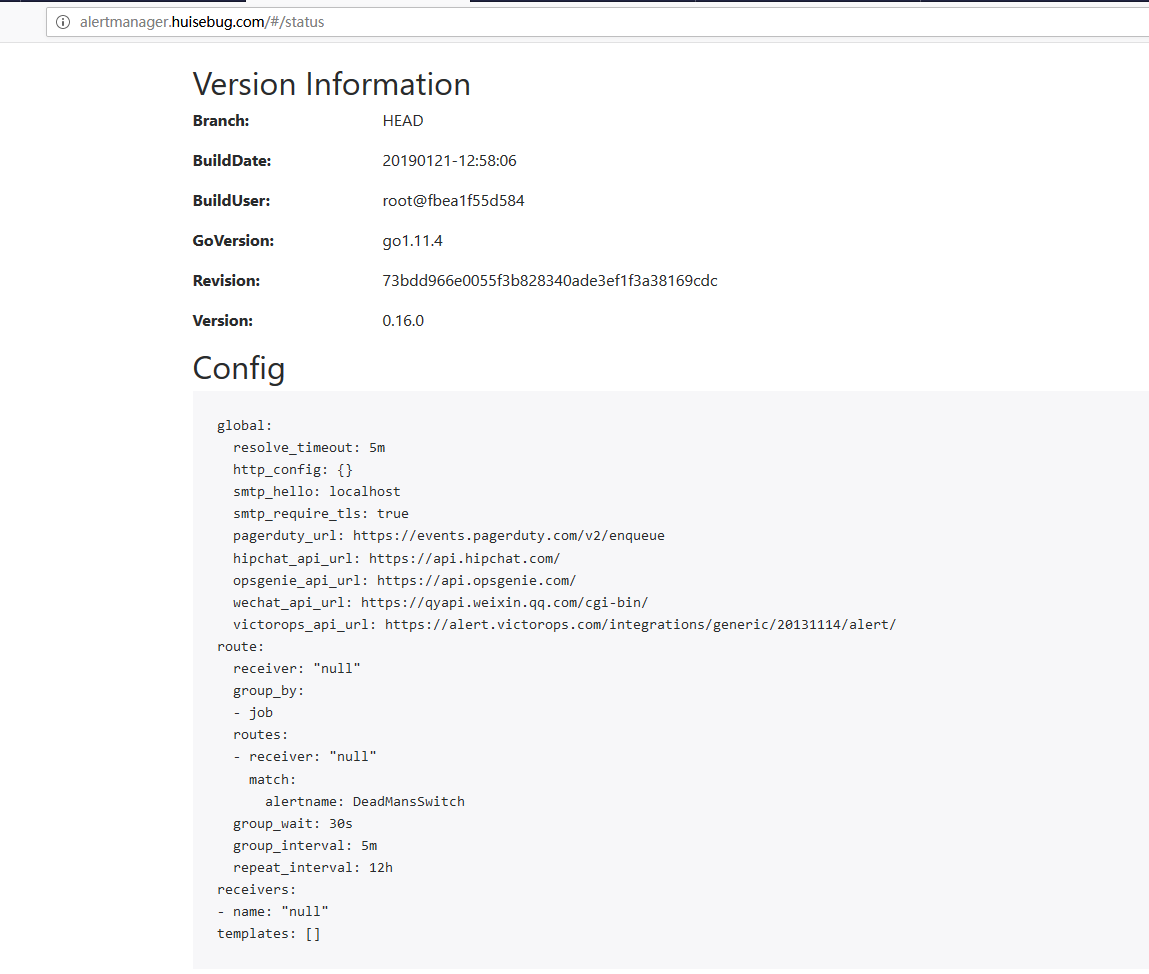
下面演示如何用钉钉群组来接收告警信息
钉钉webhook报警2.0版本8060
安装钉钉插件
物理机安装
1 | wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v0.3.0/prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gz |
物理方式安装就不过多介绍
Docker单机容器部署
钉钉webhook 容器建立
1 | docker run -d --restart=always -p 8060:8060 --name=prometheus-webhook-dingtalk timonwong/prometheus-webhook-dingtalk --ding.profile="ops_dingding=钉钉机器人处复制webhook" |
修改alertmanager.yaml内容
此处需要修改/root/prometheus-operator-history/contrib/kube-prometheus/manifests/alertmanager-secret.yaml文件,其中的data数据是经过base64加密的,复制出来随便去一个base64解码即可看到。或者运行下面的命令
1 | cat alertmanager-secret.yaml | grep alertmanager.yaml | cut -f 2- -d ":" | tr -d " " | base64 –d |
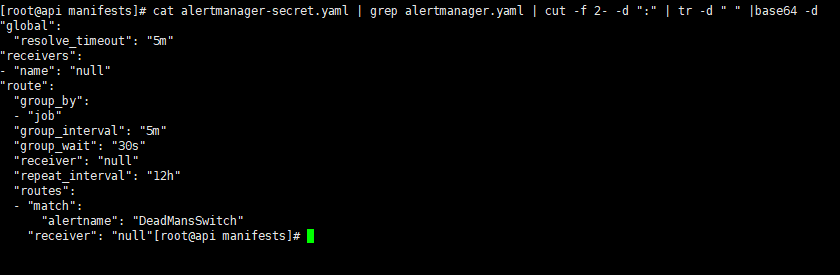
我们需要将secret中的alertmanager.yaml修改为如下的内容:
1 | global: |
上述的地址记得修改为你的服务器IP地址
首先在同一级目录下建立一个alertmanager.yaml文件,内容就是如上
运行如下命令
1 | ALT_S=$(cat alertmanager-secret.yaml | grep alertmanager.yaml | cut -f 2- -d ":" | tr -d " ") |
即可完成替换,然后重新建立secret,从之前的alertmanager-main-statefulsets.yaml文件中可以看出secret是挂载到卷的,不是环境变量的方式,这样是支持热更新的

执行修改后的secret文件
1 | kubectl apply -f alertmanager-secret.yaml |
查看是否修改成功
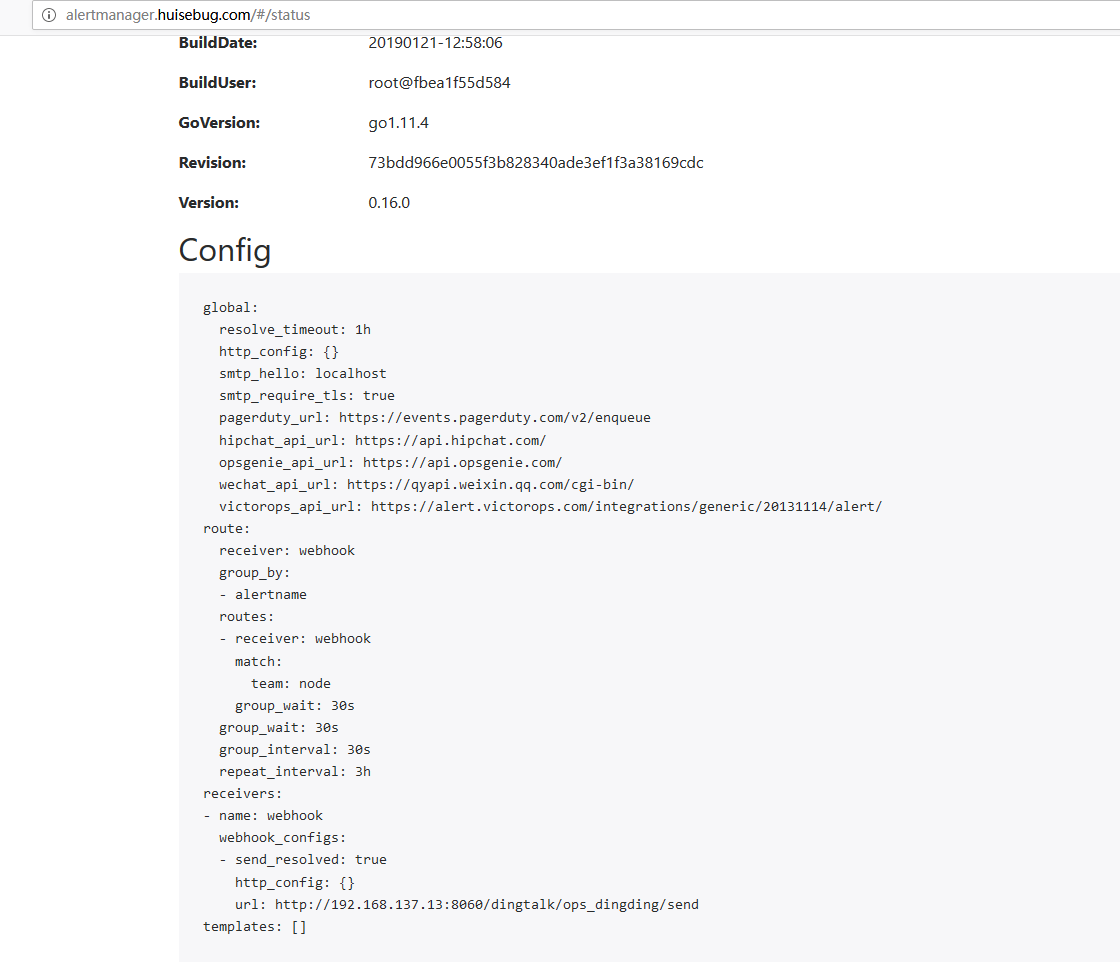
集群方式部署
都失败了,暂时放弃这种想法了。
hostnetwork方式访问
service方式访问
这种方式会存在问题
alertmanager的日志

钉钉插件日志

参考yaml文件
需要将其中的webhook设置成你的
修改alertmanager.yaml内容
此处需要修改/root/prometheus-operator-history/contrib/kube-prometheus/manifests/alertmanager-secret.yaml文件,其中的data数据是经过base64加密的,为了不与上面混淆,将其复制并命名为alertmanager-secret-k8sdd.yaml
我们需要将secret中的alertmanager.yaml修改为如下的内容:
1 | global: |
首先在同一级目录下建立一个alertmanager-k8sdd.yaml文件,内容就是如上,修改了地址为service名称
运行如下命令,记住alertmanager-k8sdd.yaml不能存在注释符号
1 | ALT_S=$(cat alertmanager-secret-k8sdd.yaml | grep alertmanager.yaml | cut -f 2- -d ":" | tr -d " ") |
上述方法我感觉是钉钉插件镜像的代码问题,镜像作者也很久未更新了,所以暂时放弃service方式访问
企业微信报警
后续的所有操作都可在以下GitHub地址找到
https://github.com/huisebug/Prometheus-Operator
后续演示的还是基于官方的github来操作
建立企业微信账户
step 1: 访问网站https://work.weixin.qq.com/ 注册企业微信账号(不需要企业认证)。
step 2: 访问apps 创建应用,点击 创建应用按钮 -> 填写应用信息:
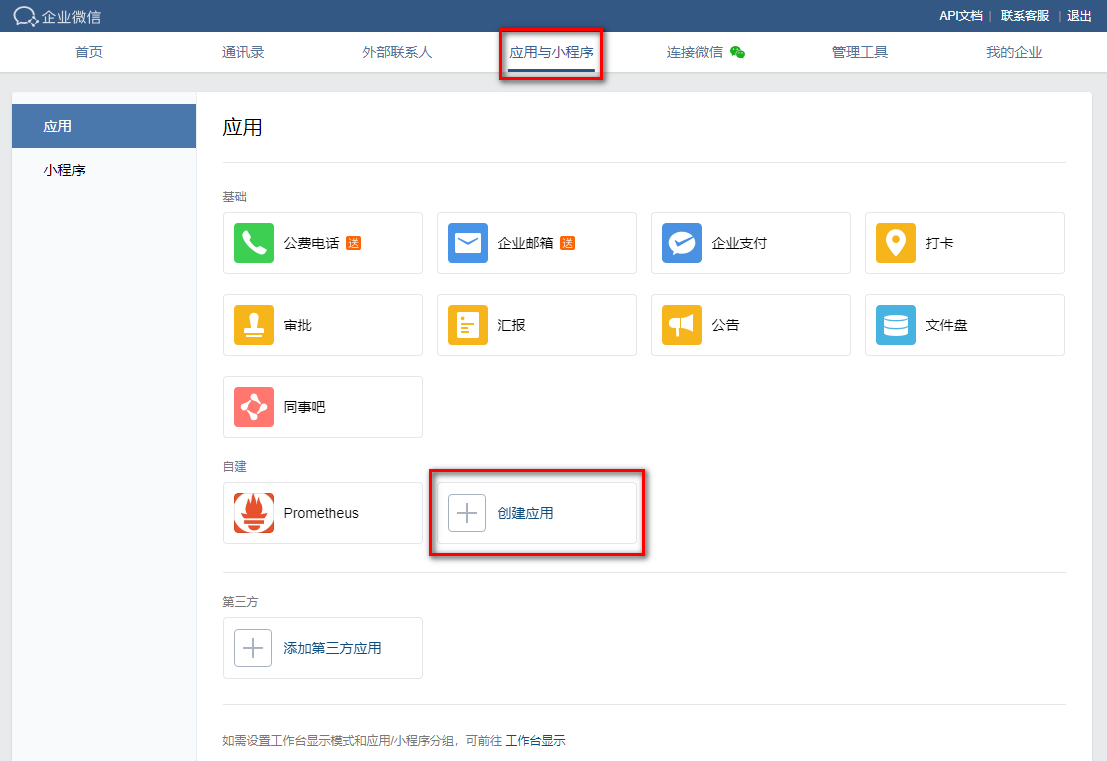
如果有则忽略
修改alertmanager.yaml内容
此处需要修改kube-prometheus/manifests/alertmanager-secret.yaml文件,其中的data数据是经过base64加密的,复制出来随便去一个base64解码即可看到。或者运行下面的命令
1 | cat alertmanager-secret.yaml | grep alertmanager.yaml | cut -f 2- -d ":" | tr -d " " | base64 –d |
我们需要将secret中的alertmanager.yaml修改为如下的内容:
1 | global: |
- corp_id: 企业微信账号唯一 ID, 可以在”我的企业”中查看。
- to_party: 需要发送的组(部门ID)。即

- agent_id: 第三方企业应用的 ID,可以在自己创建的第三方企业应用详情页面查看。
- api_secret:第三方企业应用的密钥,可以在自己创建的第三方企业应用详情页面查看。
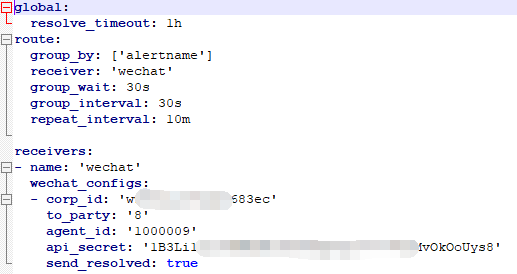
将上面修改好的内容进行base64加密,然后copy到alertmanager-secret.yaml中,然后在alertmanager web页面进行查看
建立资源类型PrometheusRule
默认的在建立Prometheus-Operator时候会建立官方推荐的一些告警规则,为便于测试,可暂时删除prometheus-rules.yaml中的资源类型PrometheusRule规则
1 | kubectl --kubeconfig=./kubeconfig/sre.kubeconfig delete -f kube-prometheus/manifests/prometheus-rules.yaml |
然后执行我新建的一些简单告警规则资源类型PrometheusRule(服务状态规则,mysql服务状态规则)
1 | kubectl --kubeconfig=./kubeconfig/sre.kubeconfig apply -f kube-prometheus/manifests/new/mysql-rules.yaml |
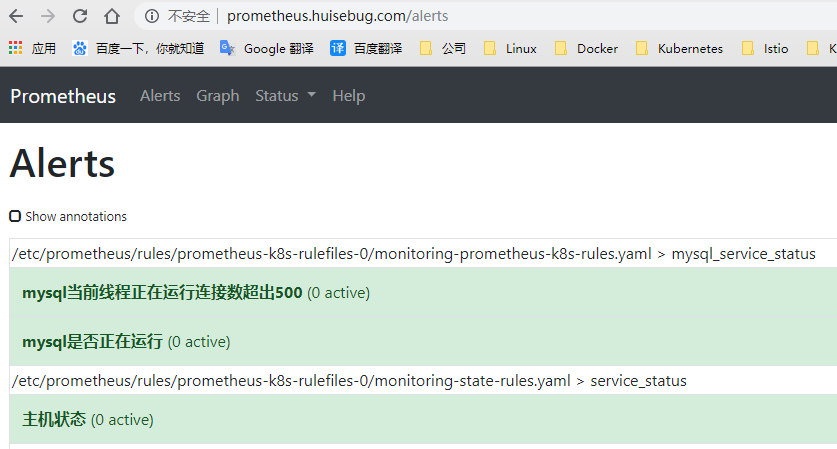
建立对应的告警目标服务
根据上面我们建立的告警规则,我们需要建立mysql服务,mysql监控服务
1 | kubectl --kubeconfig=./kubeconfig/sre.kubeconfig apply -f kube-prometheus/manifests/new/mysql-rc.yaml |

在prometheus web页面查看

验证告警效果
注意验证方法,MySQL服务自身是没有提供metrics,是依靠mysql-exporter这个服务去收集的,所以当MySQL服务无法访问的时候才能实现mysql告警,MySQL-exporter服务停止是服务停止告警,此处我需要将mysql服务的service配置删除,已达到服务无法访问的效果
1 | kubectl.exe --kubeconfig=./kubeconfig/sre.kubeconfig get svc |
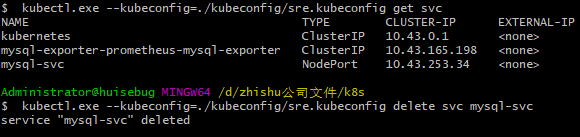
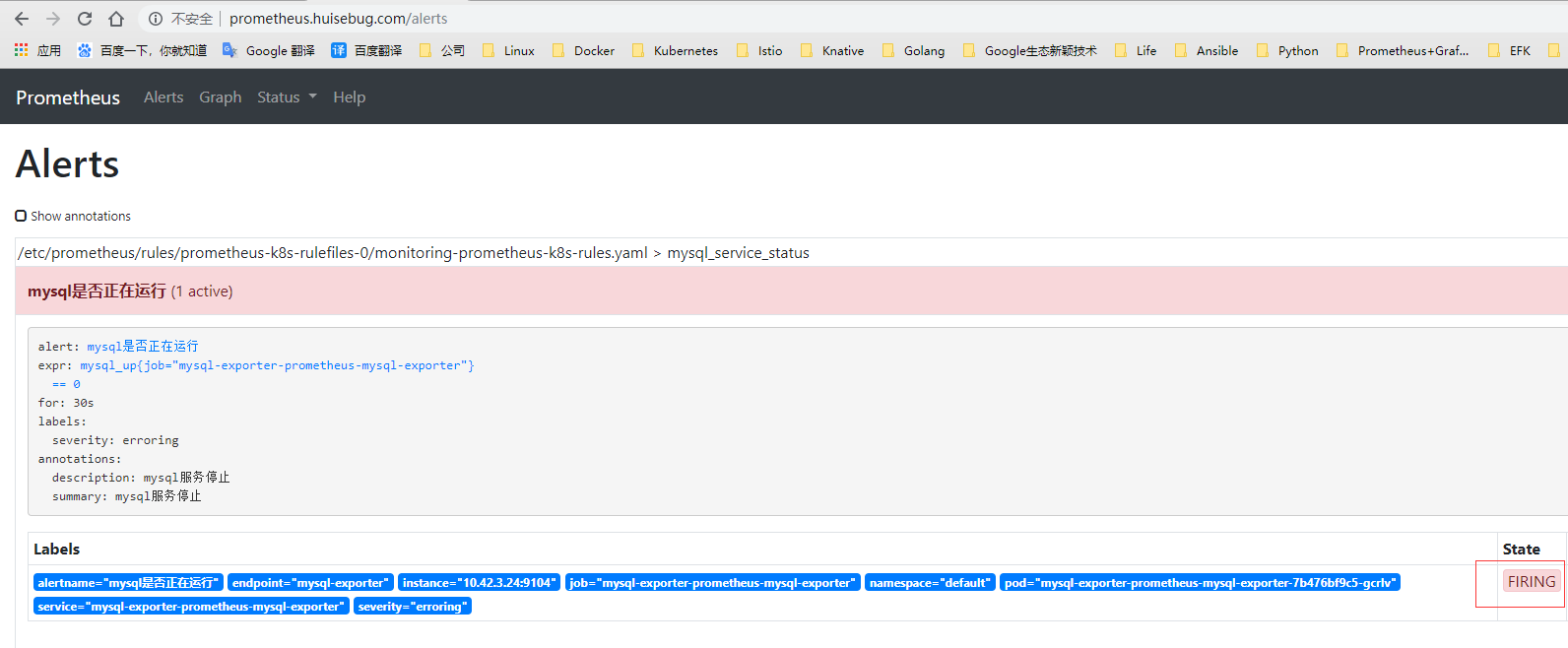
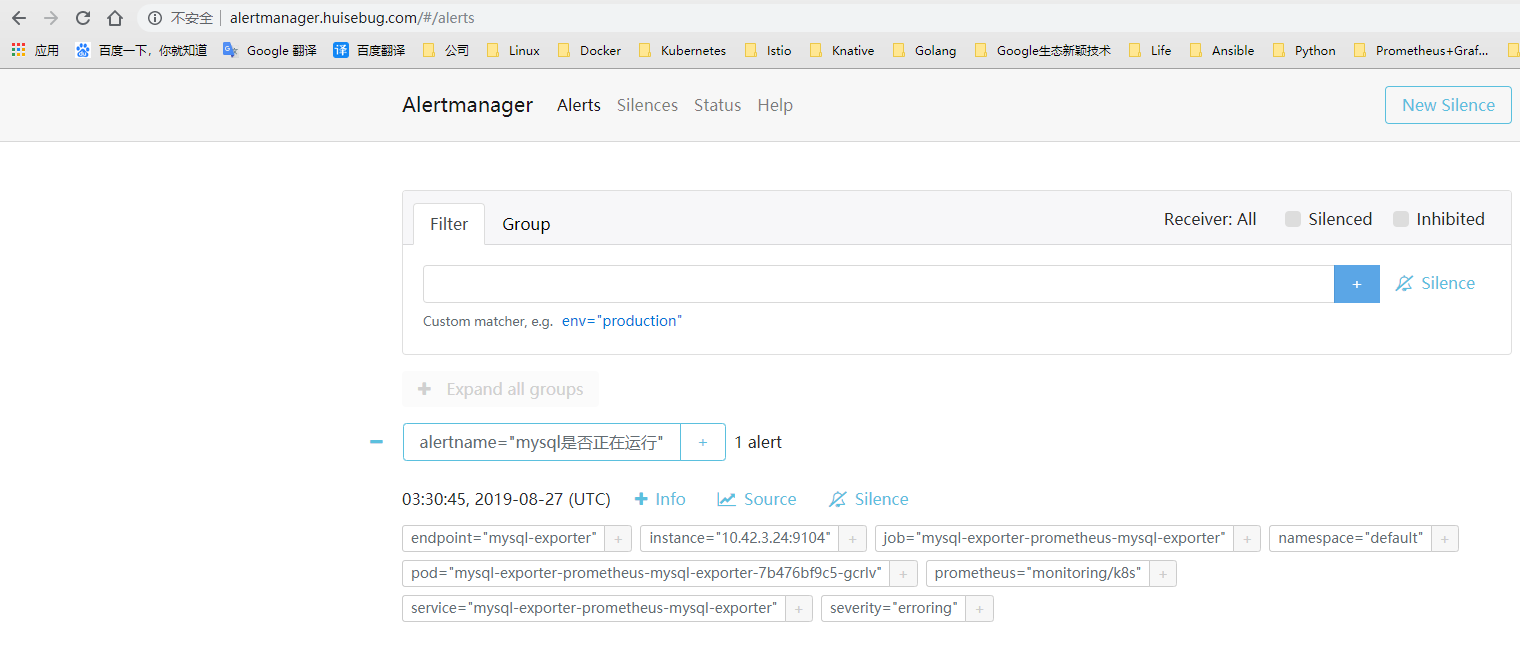
30秒后就可以在两个控制台分别看到如下
企业微信客户端收到错误告警如下

重新建立svc,验证恢复告警
1 | kubectl --kubeconfig=./kubeconfig/sre.kubeconfig apply -f kube-prometheus/manifests/new/mysql-rc.yaml |

总结:
- 告警信息太多,太杂乱
- 错误告警和恢复告警基本内容差不多,无法区别
- 需要自定义告警模板来便于快速定位
建立自定义告警模板
alertmanager-temp-configmap.yaml

上面的模板是使用的gotemplate语法编写,其中包含了错误告警和恢复告警,具体编写请参考以下链接
https://github.com/songjiayang/prometheus_practice/issues/12
修改alertmanager.yaml内容
我们需要将secret中的alertmanager.yaml修改为如下的内容:
1 | global: |
- templates:指定告警模板的存放位置,注意此处的路径是固定格式的/etc/alertmanager/configmaps/+configmap名称+configmap中的键名,即我在new目录下的alertmanager-temp-configmap.yaml,如下:
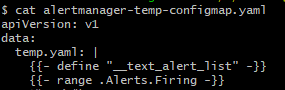
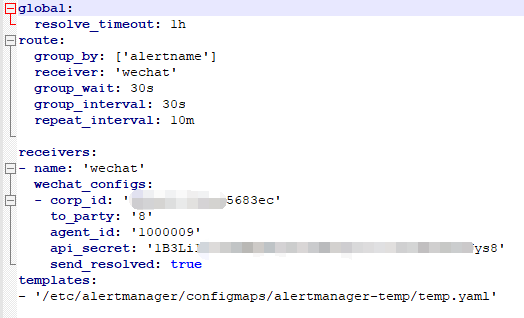
将上面修改好的内容进行base64加密,然后copy到alertmanager-secret.yaml中,然后在alertmanager web页面进行查看
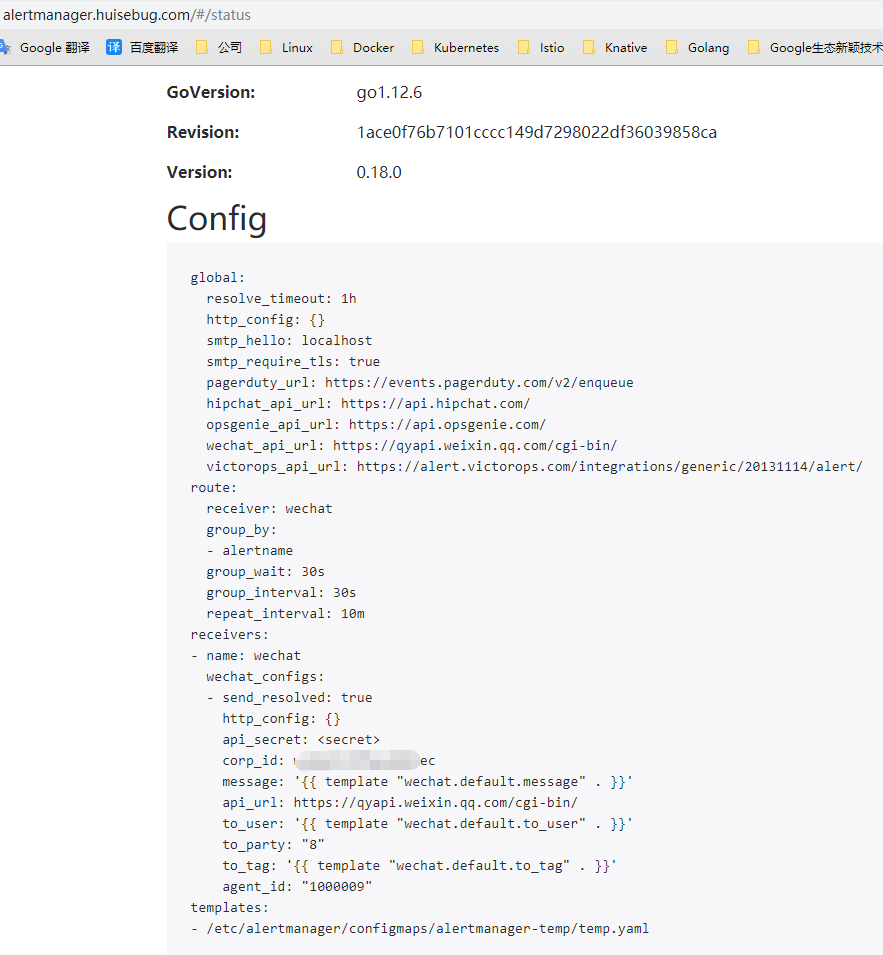
alertmanager服务添加configmap挂载
alertmanager服务的建立是statefulset建立的,是依据alertmanager-alertmanager.yaml文件建立的,需要增加自定义模板的configmap挂载,并且默认是挂载到/etc/alertmanager/configmaps/下的,可参照官方介绍https://github.com/coreos/prometheus-operator/blob/master/Documentation/api.md#alertmanagerspec
修改如下:
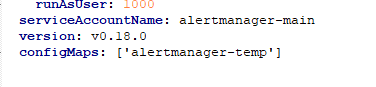
所以需要重新建立alertmanager服务
1 | kubectl --kubeconfig=./kubeconfig/sre.kubeconfig apply -f kube-prometheus/manifests/alertmanager-alertmanager.yaml |
再次验证告警效果,同样的删除mysql的svc。企业微信效果如下


企业微信/QQmail同时报警
配置文件如下
1 | global: |
 wechat
wechat alipay
alipay






